Towards Making Systems Forget with Machine Unlearning
Qué hace
Este paper introduce formalmente el concepto de machine unlearning: la capacidad de un sistema de aprendizaje automático de “olvidar” datos específicos sin necesidad de reentrenar desde cero. Es el trabajo fundacional del área.
Metodología
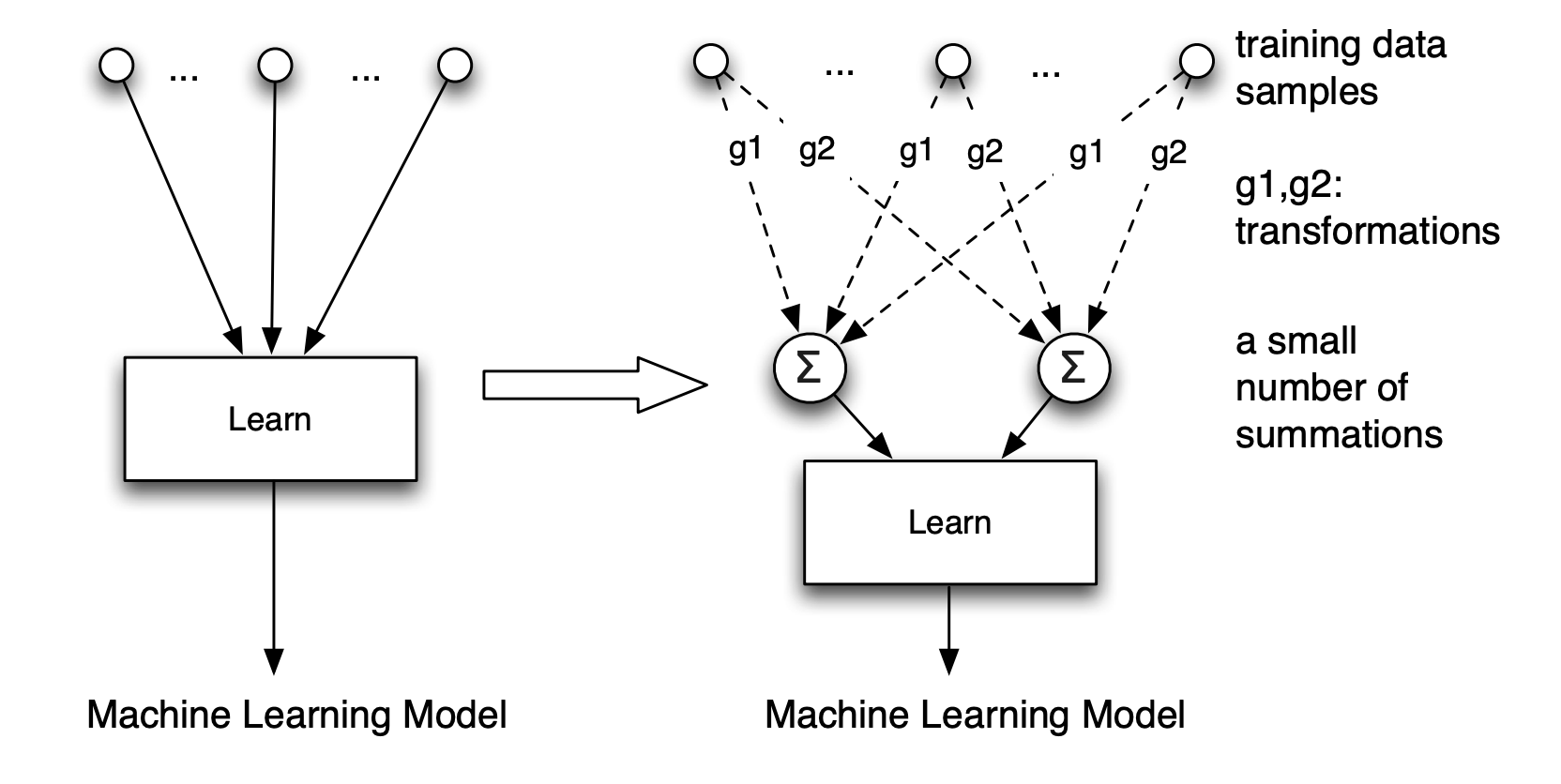
El problema clave es que los modelos de ML aprenden representaciones que mezclan información de todos los datos de entrenamiento, haciendo que “borrar” un dato sea difícil. La solución propuesta es reformular el proceso de entrenamiento usando sumas estadísticas (summation form).
La idea central es que muchos algoritmos de ML (como regresión logística, SVMs) pueden expresarse como funciones que operan sobre estadísticas agregadas de los datos (sumas, productos) en lugar de sobre los datos individuales directamente. Si el sistema guarda estas sumas intermedias, entonces eliminar el aporte de un dato específico se reduce a restar su contribución de esa suma y actualizar el modelo a partir de las sumas modificadas.
Esto funciona a nivel de los parámetros del modelo completo: no se tocan capas individuales ni neuronas, sino los coeficientes del modelo. Para algoritmos lineales o basados en kernels, el proceso es exacto y muy eficiente.
Para modelos más complejos (como redes neuronales), proponen una aproximación: dividir el modelo en “shards” o fragmentos, donde cada fragmento aprende de un subconjunto de datos. Para olvidar un dato, sólo se re-entrena el fragmento que lo contenía, no el modelo completo.
Datasets utilizados
- UCI ML Repository: datasets de clasificación como Adult (ingresos), MNIST (dígitos escritos a mano), datasets de detección de intrusiones de red.
- Se usan datasets relativamente pequeños, ya que el contexto de aplicación original es sistemas de ML tradicionales, no LLMs.
Ejemplo ilustrativo
Imaginá que entrenas un clasificador de spam con 10 millones de correos. Luego un usuario pide que se eliminen sus 500 correos del modelo (derecho al olvido — GDPR). Sin machine unlearning, tendrías que reentrenar desde cero con los 9.999.500 correos restantes: horas o días de computación. Con machine unlearning basado en sumatorias, simplemente restás la contribución estadística de esos 500 correos y actualizas los pesos en segundos.
Resultados principales
- El método logra olvidar datos específicos de manera exacta (sin rastros estadísticos detectables) para modelos lineales.
- La velocidad de desaprendizaje es varios órdenes de magnitud más rápida que el reentrenamiento completo.
- Para modelos basados en shards, el overhead de almacenamiento es manejable y el tiempo de desaprendizaje crece logarítmicamente con el tamaño del dataset.
Ventajas respecto a trabajos anteriores
Antes de este paper, la única opción para “olvidar” datos era reentrenar el modelo completamente desde cero, lo cual es prohibitivamente costoso. Este trabajo:
- Formaliza el problema de machine unlearning por primera vez.
- Propone el primer mecanismo eficiente y con garantías teóricas de olvido exacto.
- Establece los criterios que todo método de unlearning debe cumplir: completitud (el dato fue olvidado), rapidez (más rápido que reentrenar), y preservación del rendimiento.
Trabajos previos relacionados
Este paper no tiene una sección formal de “Related Work” —es el trabajo fundacional del área— pero en la introducción y el desarrollo contextualiza el problema frente a trabajos previos en privacidad, seguridad y aprendizaje automático.
- Dwork et al. (2006) — Differential Privacy: introduce la privacidad diferencial como garantía matemática de que los datos individuales no pueden inferirse desde el modelo; Cao & Yang la citan como alternativa costosa a su propuesta de unlearning exacto.
- Chaudhuri & Monteleoni (2009) — Privacy-preserving logistic regression: uno de los primeros trabajos en entrenamiento con privacidad para modelos de clasificación; motiva la búsqueda de alternativas post-hoc como el unlearning.
- Shalev-Shwartz & Ben-David (2014) — Understanding Machine Learning: provee el marco teórico de Empirical Risk Minimization sobre el que Cao & Yang definen formalmente el problema de unlearning.
- Ginart et al. (2019) — Making AI Forget You: extiende directamente las ideas de Cao & Yang al caso de datos continuos y k-means, siendo una continuación directa de este trabajo fundacional.
- Bourtoule et al. (2021) — Machine Unlearning via SISA: propone el enfoque SISA (Sharded, Isolated, Sliced, Aggregated) de re-entrenamiento eficiente, inspirado directamente en la arquitectura de “shards” de este paper.
- Mantelero (2013) — The EU Proposal for a General Data Protection Regulation: artículo legal que formaliza el “derecho al olvido” (Right to be Forgotten), motivación regulatoria central de todo el trabajo de machine unlearning.
- Calandrino et al. (2011) — You Might Also Like: Privacy Risks of Collaborative Filtering: demuestra que los sistemas de recomendación memorizan y filtran datos de entrenamiento, contextualizando la amenaza que machine unlearning busca mitigar.
Tags
machine-unlearning privacidad derecho-al-olvido modelos-lineales eficiencia-computacional