FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
Qué hace
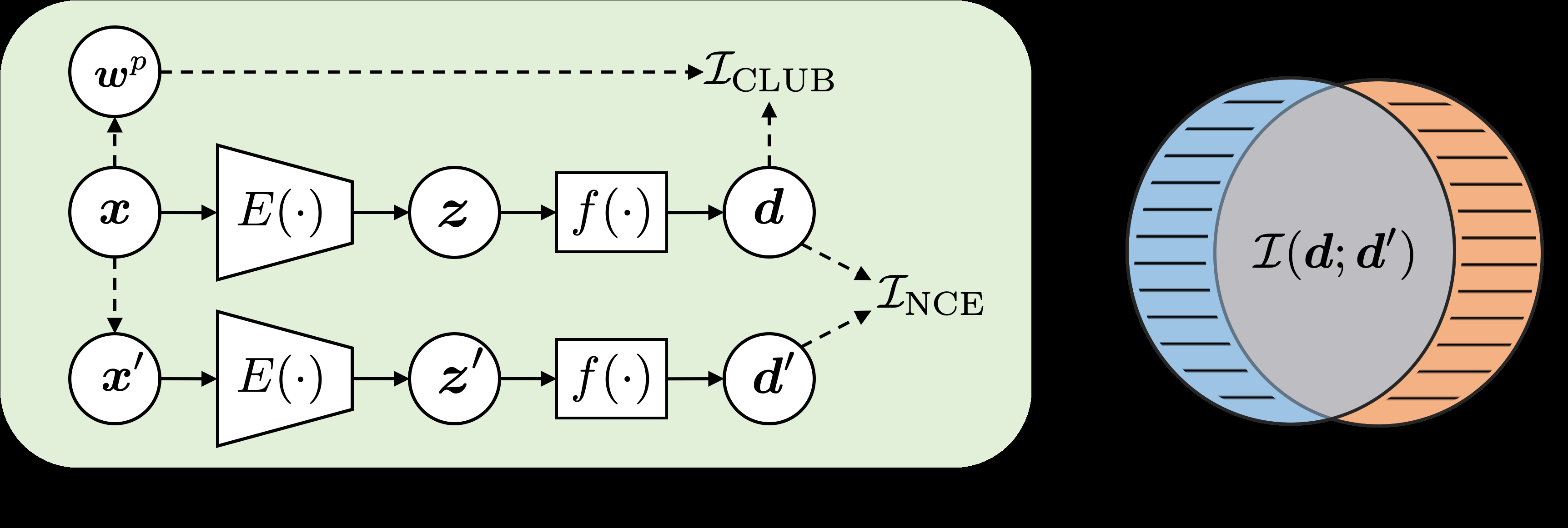
Propone FairFil (Fair Filter), el primer método de debiasing neuronal a nivel de oración para encoders de texto preentrenados como BERT. La idea central es añadir una pequeña red neuronal extra (“filtro”) que transforma las representaciones de oraciones del encoder original en representaciones debiasiadas, sin necesidad de reentrenar el encoder base.
FairFil opera como un post-procesador diferenciable: toma los embeddings de oraciones de BERT y los proyecta a un espacio donde la correlación con palabras de sesgo (géneros, etnias, religiones) es mínima, pero la información semántica útil se conserva. El entrenamiento usa aprendizaje contrastivo.
Metodología
FairFil tiene dos componentes:
1. Red FairFil (el filtro): Es una red neuronal pequeña (típicamente 2-3 capas MLP) que recibe el embedding de oración de BERT y produce un embedding “filtrado”. No modifica los pesos de BERT.
2. Función de pérdida contrastiva: Se construyen tripletas de entrenamiento: (anchor, positivo, negativo). El anchor es una oración neutral; el positivo es la misma oración con el atributo protegido cambiado (e.g., cambio de género); el negativo es una oración semánticamente diferente pero con el mismo atributo protegido.
La pérdida tiene dos términos:
- Término de equidad: Minimiza la distancia entre anchor y positivo en el espacio filtrado (las versiones de género opuesto deben tener representaciones similares).
- Término de preservación semántica: Maximiza la distancia entre anchor y negativo, y minimiza la distancia entre representaciones originales y filtradas de oraciones sin sesgo.
Al final del entrenamiento, solo se usa la red FairFil en inferencia — se descarta el encoder BERT original y se usa BERT+FairFil como un encoder compuesto.
Datasets utilizados
- SentiBias: Corpus de oraciones con plantillas género-neutrales para entrenamiento de FairFil.
- STS-B (Semantic Textual Similarity): Para evaluar si FairFil preserva la información semántica.
- SEAT (Sentence Encoder Association Test): Para medir el bias residual en el encoder filtrado.
- SST-2 (Stanford Sentiment Treebank): Para evaluar rendimiento en tarea downstream de análisis de sentimiento.
Ejemplo ilustrativo
BERT sin FairFil: los embeddings de “The programmer was a man” y “The programmer was a woman” tienen una distancia coseno de 0.35 (muy diferentes). Esto refleja el sesgo del modelo: el género cambia significativamente la representación de “programmer”.
BERT+FairFil: la distancia coseno entre los mismos embeddings filtrados es 0.04 (casi idénticos). El filtro ha eliminado la información de género del embedding sin alterar la representación de “programmer” como profesión.
En una tarea de búsqueda semántica, la precisión en STS-B solo cae 0.8 puntos respecto a BERT sin filtro, mientras el SEAT bias score cae un 40%.
Resultados principales
- FairFil reduce el bias en SEAT en un 40-60% respecto a BERT base sin debiasing.
- La caída en tareas downstream (STS-B, SST-2) es menor que la de métodos de proyección de subespacio (SentenceDebias, INLP).
- Al ser un post-procesador, es compatible con cualquier encoder preentrenado sin necesidad de acceder al proceso de preentrenamiento.
- Los experimentos de ablación muestran que ambos términos de la pérdida son necesarios: sin el término de preservación semántica, el modelo colapsa a representaciones uniformes.
Ventajas respecto a trabajos anteriores
- Es el primer método de debiasing neuronal a nivel de oración: los métodos anteriores (SentenceDebias, INLP) usan proyecciones lineales rígidas que pueden destruir información semántica.
- Al ser post-hoc, no requiere reentrenamiento del encoder base, lo que lo hace aplicable a modelos propietarios o de gran escala.
- El aprendizaje contrastivo preserva mejor las relaciones semánticas que las técnicas de eliminación de subespacio.
- Es más expresivo que los métodos lineales al poder capturar correlaciones no lineales entre embeddings y atributos de sesgo.
Trabajos previos relacionados
- Bolukbasi et al. (2016) — Man is to Computer Programmer as Woman is to Homemaker: debiasing por proyección en subespacio para word embeddings estáticos; FairFil extiende esta idea a representaciones de oraciones con redes neuronales.
- Liang et al. (2020) — SentenceDebias: extensión de Hard-Debias a nivel de oración; la comparación directa con FairFil muestra que la red neuronal preserva mejor la semántica.
- Ravfogel et al. (2020) — INLP: elimina iterativamente el subespacio lineal del atributo protegido; FairFil captura correlaciones no lineales que INLP pierde.
- He et al. (2022) — MABEL: debiasing contrastivo con pares de implicación textual; el objetivo de MABEL es similar al de FairFil pero opera en el espacio de NLI en lugar de usar tripletas de filtrado.
- Meade et al. (2021) — An Empirical Survey of Debiasing Techniques: evaluación comparativa donde FairFil aparece como uno de los baselines principales.
Tags
debiasing contrastive-learning sentence-encoder BERT post-hoc fair-filter