Calibrate Before Use: Improving Few-Shot Performance of Language Models
Qué hace
Descubre que el rendimiento de few-shot learning en GPT-3 está altamente influenciado por sesgos en los prompts (orden de ejemplos, elección de ejemplos, formato) y propone una técnica de calibración que normaliza las predicciones del modelo para reducir estos sesgos.
Metodología
El problema: En few-shot learning, GPT-3 recibe un prompt con K ejemplos de demostración y una pregunta. El rendimiento varía dramáticamente dependiendo de:
- Label bias: si en los ejemplos de demostración una etiqueta aparece más veces que otra, el modelo aprende a predecir esa etiqueta más frecuentemente.
- Recency bias: el modelo tiende a repetir la etiqueta del último ejemplo de demostración.
- Token bias: algunas etiquetas tienen mayor probabilidad base sólo por sus tokens (ej. “Positive” tiene mayor probabilidad que “Negative” de base).
La solución — Calibración: Se introduce un “input de contenido vacío” (content-free input): un texto que no tiene información sobre la tarea (ej. “N/A” o “___”). Se mide la distribución de probabilidad del modelo sobre las etiquetas posibles dado este input vacío. Esta distribución revela los sesgos del modelo:
-
Si P(“Positive” “N/A”) = 70% y P(“Negative” “N/A”) = 30%, el modelo tiene label bias hacia “Positive”.
La calibración: Se normalizan todas las predicciones del modelo dividiendo por la distribución de bias. Si el modelo asigna P(“Positive”) = 70% para el input vacío, para cualquier input real se divide la probabilidad de “Positive” por 0.7.
Esto sólo modifica los logits del output del modelo en tiempo de inferencia — los pesos del modelo NO se cambian. Es una post-corrección puramente analítica.
Datasets utilizados
- SST-2: análisis de sentimientos.
- AGNews: clasificación de noticias (4 categorías).
- TREC: clasificación de preguntas (6 categorías).
- DBPedia: clasificación de entidades (14 categorías).
- RTE: inferencia textual binaria.
- Evaluado en GPT-3 (varios tamaños).
Ejemplo ilustrativo
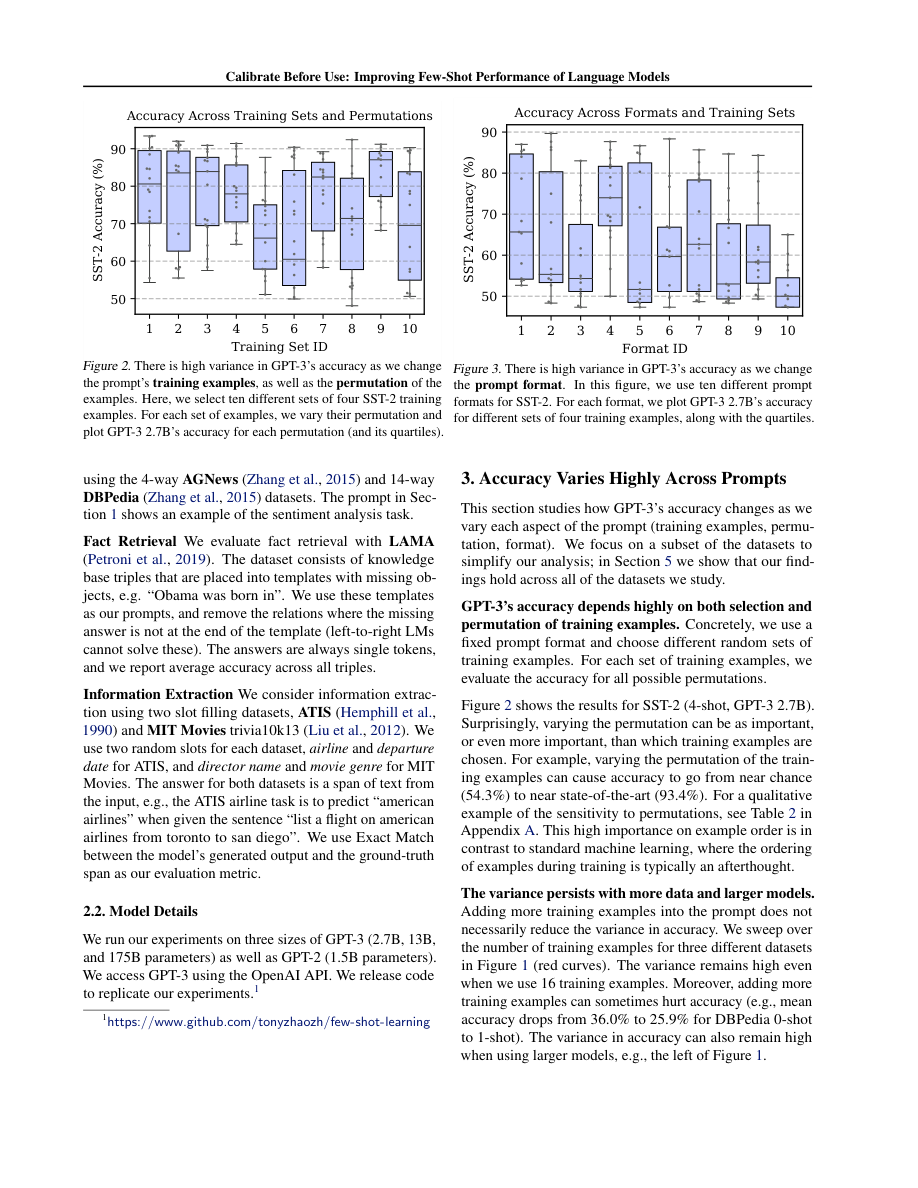
En un prompt few-shot para clasificación de sentimiento con 4 ejemplos positivos y sólo 2 negativos, el modelo predice “Positive” el 80% del tiempo incluso para inputs negativos (label bias + recency bias).
| La calibración mide P(Positive | “N/A”) = 65%, normaliza las predicciones dividiendo por 0.65, y el modelo vuelve al ~50-55% de predicciones positivas, mucho más alineado con la distribución real. |
Resultados principales
- La calibración mejora la accuracy en few-shot en todos los datasets evaluados: +5-15% dependiendo de la tarea.
- El beneficio es mayor cuando los ejemplos de demostración están desbalanceados.
- La técnica es robusta: funciona independientemente del orden de los ejemplos y del tamaño del modelo.
- Revela que gran parte de la varianza en rendimiento few-shot reportada en papers previos se debe a estos sesgos corregibles.
Ventajas respecto a trabajos anteriores
- Primer estudio sistemático de los sesgos del prompt en few-shot GPT-3.
- La calibración es trivialmente simple (dos forward passes: uno para el input real, uno para “N/A”) y muy efectiva.
- Revela que el rendimiento de few-shot no es tan “mágico” como se pensaba: gran parte es sesgo del prompt corregible.
Trabajos previos relacionados
El paper organiza los trabajos previos en tres grupos: (1) few-shot learning con modelos de lenguaje, (2) volatilidad e inestabilidades del few-shot, y (3) fallos de los modelos de lenguaje.
- Brown et al. (2020) — Language Models are Few-Shot Learners (GPT-3): presenta el paradigma de in-context learning que este paper analiza críticamente, demostrando que el remarkable rendimiento few-shot reportado en ese trabajo depende en parte de sesgos del prompt.
- Radford et al. (2019) — Language Models are Unsupervised Multitask Learners (GPT-2): demuestra rendimiento zero-shot razonable en tareas NLP sin entrenamiento adicional, primer paso hacia el in-context learning que este paper calibra.
- Petroni et al. (2019) — Language Models as Knowledge Bases?: usa LMs para completar consultas de conocimiento factual y muestra que pequeñas variaciones en el formato afectan drásticamente el recall, motivación directa de la inestabilidad estudiada aquí.
- Jiang et al. (2020) — How Can We Know What a Language Model Knows?: demuestra que el rendimiento zero-shot varía según la formulación del prompt, trabajo independiente que documenta la misma inestabilidad que este paper analiza y mitiga.
- Shin et al. (2020) — AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts: propone buscar automáticamente prompts óptimos, enfoque complementario al de calibración propuesto aquí.
- Gao et al. (2020) — Making Pre-trained Language Models Better Few-shot Learners: muestra que para fine-tuning en pocos ejemplos, la elección de ejemplos de entrenamiento tiene gran impacto, trabajo paralelo que documenta inestabilidades similares en modelos enmascarados (BERT).
- Schick & Schütze (2020) — It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners (PET): fine-tunea modelos BERT en pocos ejemplos con patrones de verbalizador, mostrando que los prompts importan también fuera del régimen GPT-3.
- Holtzman et al. (2020) — The Curious Case of Neural Text Degeneration: identifica el problema de repetición en LMs generativos y propone nucleus sampling, un ejemplo de fallo de LMs que se mitiga modificando probabilidades de output, análogo al enfoque de calibración de este paper.
- Khandelwal et al. (2018) — Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context: documenta recency bias en LMs de secuencias largas, precursor del análisis de recency bias en few-shot que hace este paper.
Tags
few-shot-learning calibración sesgo-de-prompt GPT-3 evaluación