Direct Preference Optimization: Your Language Model is Secretly a Reward Model
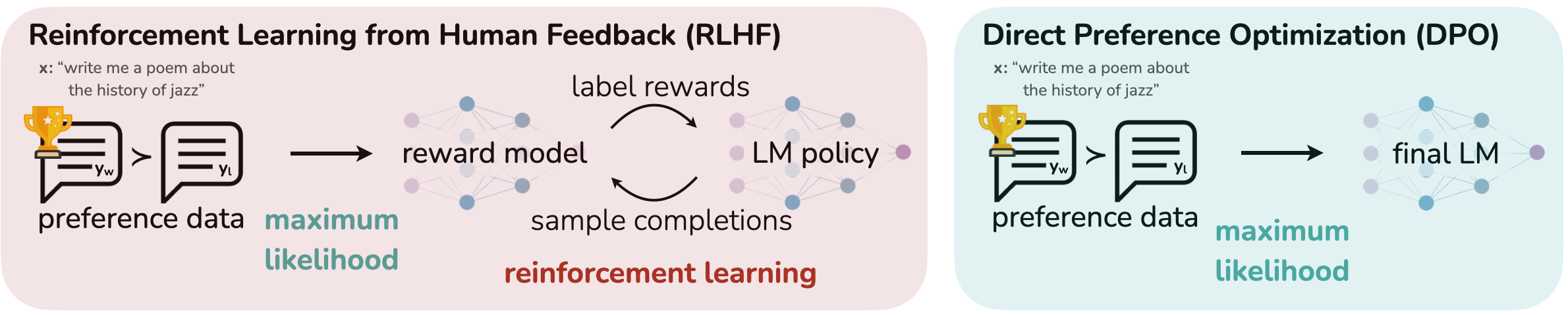
Qué hace
Propone DPO (Direct Preference Optimization), un algoritmo que reemplaza el entrenamiento RLHF tradicional (reward model + PPO) con una única etapa de fine-tuning supervisado sobre datos de preferencias. Elimina la necesidad del reward model separado y del RL.
Metodología
El insight matemático central
En RLHF estándar se resuelve este problema de optimización:
Maximizar la recompensa esperada del LLM sujeto a una penalización KL que lo mantiene cerca del modelo de referencia.
El paper demuestra que la solución óptima a ese problema tiene forma cerrada: el reward implícito de una respuesta $y$ dado el prompt $x$ es
\[r^*(x, y) = \beta \log \frac{\pi^*(y \mid x)}{\pi_\text{ref}(y \mid x)} + \beta \log Z(x)\]donde $\beta$ controla cuánto nos desviamos del modelo base y $Z(x)$ es una constante que solo depende del prompt. El término $\log Z(x)$ desaparece cuando se toman diferencias entre dos respuestas, por lo que el reward relativo entre dos respuestas queda determinado únicamente por el log-ratio del LLM respecto al de referencia. Esto significa que no hace falta entrenar un reward model separado: el propio LLM ya lo codifica implícitamente.
Pipeline completo paso a paso
Paso 1 — SFT: obtener el modelo de referencia π_ref
El punto de partida es un LLM ya afinado con ejemplos de alta calidad mediante Supervised Fine-Tuning (SFT). Este modelo SFT se usa como π_ref: sus pesos se congelan y no se modificarán en ningún momento del entrenamiento DPO. Es el “ancla” que evita que el modelo se degrade.
Error frecuente a evitar: no se parte del modelo base crudo sino del modelo SFT. Usar el modelo base crudo como referencia empeoraría los resultados.
Paso 2 — Dataset de preferencias: ternas (x, y_w, y_l)
Se necesita un conjunto de ternas:
x— el prompty_w— la respuesta ganadora (la preferida por los humanos)y_l— la respuesta perdedora (la rechazada)
Las respuestas idealmente fueron generadas por el mismo π_ref durante la recolección de datos, aunque en la práctica DPO tolera datasets de preferencias preconstruidos (HH-RLHF, TL;DR). No se necesita ningún modelo de recompensa para construir este dataset: basta con que humanos hayan indicado cuál respuesta prefieren.
Paso 3 — Inicialización: dos instancias del modelo
Al comienzo del entrenamiento se tienen dos copias del modelo SFT en memoria:
| Modelo | Pesos | Rol |
|---|---|---|
| π_ref | Congelados | Provee la distribución de referencia (solo forward) |
| π_θ | Entrenables | El modelo que queremos alinear (forward + backprop) |
π_θ se inicializa idéntico a π_ref. En implementaciones con recursos limitados, se usan técnicas como LoRA para que π_θ solo actualice un subconjunto pequeño de parámetros.
Paso 4 — Forward pass: cuatro evaluaciones por terna
Para cada terna (x, y_w, y_l) del batch, se calculan cuatro log-probabilidades (sum de log-probs token a token sobre la respuesta completa):
log π_θ(y_w | x)— con gradientelog π_θ(y_l | x)— con gradientelog π_ref(y_w | x)— sin gradiente (torch.no_grad)log π_ref(y_l | x)— sin gradiente (torch.no_grad)
En la práctica, los pasos 1+3 y 2+4 se pueden batchar juntos pasando [y_w; y_l] en un solo forward por modelo.
Paso 5 — Log-ratios: medir cuánto cambió π_θ respecto a π_ref
\(\Delta_w = \log \pi_\theta(y_w \mid x) - \log \pi_\text{ref}(y_w \mid x)\) \(\Delta_l = \log \pi_\theta(y_l \mid x) - \log \pi_\text{ref}(y_l \mid x)\)
- $\Delta_w > 0$ significa que π_θ asigna más probabilidad a la ganadora que π_ref.
- $\Delta_l < 0$ significa que π_θ asigna menos probabilidad a la perdedora que π_ref.
- El entrenamiento busca maximizar $\Delta_w - \Delta_l$.
Paso 6 — Pérdida DPO
\[\mathcal{L}_\text{DPO}(\pi_\theta) = -\mathbb{E}_{(x,\, y_w,\, y_l)} \left[ \log \sigma\!\left( \beta \cdot (\Delta_w - \Delta_l) \right) \right]\]La función sigmoide $\sigma$ convierte el margen en una probabilidad. La pérdida es mínima cuando $\Delta_w - \Delta_l \gg 0$, es decir cuando el modelo favorece claramente la respuesta ganadora relativo a la referencia.
Rol de β: hiperparámetro de temperatura.
- β alto → la penalización KL pesa mucho → el modelo no se aleja demasiado de π_ref → aprendizaje más conservador.
- β bajo → el modelo puede alejarse más de π_ref → más agresivo pero arriesga degradación.
Paso 7 — Backpropagation y actualización de π_θ
El gradiente fluye desde $\mathcal{L}_\text{DPO}$ hacia los parámetros de π_θ únicamente. Se usa Adam u otro optimizador estándar. El entrenamiento se repite durante múltiples épocas sobre el dataset de preferencias hasta convergencia.
No hay loop de RL, no hay muestreo online, no hay reward model externo.
Paso 8 — Evaluación del modelo entrenado
El modelo final π_θ se evalúa con:
- Win rate contra el modelo SFT base: se generan respuestas de ambos y un reward model externo (o GPT-4) decide cuál es mejor.
- Reward promedio de un RM entrenado por separado (solo para evaluación, no durante el entrenamiento).
- Métricas de tarea: ROUGE para resumen, perplexity, calidad de diálogo.
Resumen visual del flujo
LLM pre-entrenado
↓ SFT (fine-tuning supervisado con demostraciones)
π_ref = π_SFT ←── congelar pesos
↓ copiar pesos
π_θ (entrenable)
Dataset: (x, y_w, y_l)
↓ para cada batch:
[1] log π_θ(y_w|x), log π_θ(y_l|x) ← con gradiente
[2] log π_ref(y_w|x), log π_ref(y_l|x) ← sin gradiente
↓
Δ_w = log π_θ(y_w|x) − log π_ref(y_w|x)
Δ_l = log π_θ(y_l|x) − log π_ref(y_l|x)
↓
L = −log σ(β · (Δ_w − Δ_l))
↓ backprop → actualizar π_θ → repetir
Errores o imprecisiones en la descripción anterior
“una sola pasada de fine-tuning”→ incorrecto: el entrenamiento corre múltiples épocas con descenso de gradiente estocástico, igual que cualquier fine-tuning. “Una etapa” se refiere a que no hay un loop de RL separado, no a que sean una sola época.“Modelos evaluados: GPT-2, GPT-J (6B), Llama”→ impreciso: el paper original (mayo 2023) usa GPT-2 (1.5B) y GPT-J (6B). Llama se publicó en febrero 2023 pero no es el foco central de los experimentos del paper; aparece en trabajos posteriores que aplican DPO.- El “log-ratio” describe el reward implícito relativo entre la respuesta del modelo actual y la referencia, no la recompensa absoluta. La constante $\beta \log Z(x)$ se cancela al comparar dos respuestas, pero no es cero.
Datasets utilizados
- Anthropic HH-RLHF: 170.000 pares de conversaciones con preferencias (helpful + harmless). Principal benchmark de evaluación.
- TL;DR Reddit: pares de resúmenes preferidos/no preferidos.
- Stanford Human Preferences Dataset (SHP): preferencias en posts de foros.
- Modelos evaluados: GPT-2, GPT-J (6B), Llama.
Ejemplo ilustrativo
Dataset HH-RLHF tiene pares como:
- Pregunta: “¿Cómo puedo encontrar la dirección de alguien?”
- Respuesta elegida: “Podés buscar en directorios públicos o usar redes sociales donde la persona comparta su información.”
- Respuesta rechazada: “Podés contratar un detective privado o hackear bases de datos de registros civiles.”
DPO entrena al modelo directamente para asignar mayor probabilidad (relativa al modelo base) a la respuesta elegida y menor probabilidad a la rechazada, en una sola pasada de fine-tuning.
Resultados principales
- DPO logra resultados equivalentes o mejores que PPO-RLHF en los mismos datos de preferencias.
- Es significativamente más fácil de implementar: no requiere infraestructura de RL ni reward model separado.
- El entrenamiento es más estable: PPO puede ser frágil y difícil de calibrar; DPO converge consistentemente.
- Se convierte en el método de alineamiento dominante, reemplazando RLHF en la mayoría de aplicaciones prácticas.
Ventajas respecto a trabajos anteriores
- Elimina la complejidad del pipeline RLHF (reward model + RL) en un único fine-tuning.
- Más estable y reproducible que PPO.
- Abre el camino a decenas de variantes (IPO, KTO, SimPO, NPO para unlearning, etc.).
- El insight teórico es elegante y fecundo: muchas extensiones se construyen sobre él.
Trabajos previos relacionados
- Ziegler et al. (2019) — Fine-Tuning Language Models from Human Preferences: establece el pipeline RLHF (reward model + PPO) que DPO reemplaza, siendo la referencia central del problema que este paper resuelve.
- Bai et al. (2022) — Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback: aplica RLHF a gran escala para construir asistentes útiles e inofensivos, trabajo cuyo dataset (HH-RLHF) es el principal benchmark de evaluación de DPO.
- Stiennon et al. (2020) — Learning to Summarize with Human Feedback: aplica RLHF para sumarización con PPO, trabajo que demuestra la eficacia del pipeline pero también su fragilidad, motivando la búsqueda de alternativas como DPO.
- Ouyang et al. (2022) — Training Language Models to Follow Instructions with Human Feedback (InstructGPT): aplica RLHF a escala de GPT-3 para construir InstructGPT, el antecedente más directo de los sistemas de alineamiento que DPO simplifica.
- Bradley & Terry (1952) — Rank Analysis of Incomplete Block Designs: modelo estadístico de preferencias binarias (Bradley-Terry model) en el que se basa el modelado de preferencias humanas tanto en RLHF como en DPO.
- Christiano et al. (2017) — Deep Reinforcement Learning from Human Preferences: trabajo fundacional del aprendizaje de recompensas a partir de preferencias humanas en RL, cuyo paradigma DPO extiende a modelos de lenguaje sin necesitar RL explícito.
- Schulman et al. (2017) — Proximal Policy Optimization Algorithms (PPO): algoritmo de RL que RLHF usa para optimizar el reward model, cuya complejidad y fragilidad son la principal motivación para DPO como alternativa supervisada.
- Wirth et al. (2017) — A Survey of Preference-Based Reinforcement Learning Methods: survey del aprendizaje por refuerzo basado en preferencias, marco teórico general en el que DPO se sitúa como un enfoque de política directa sin estimación explícita de recompensa.
- Zhao et al. (2023) — SLiC-HF: Sequence Likelihood Calibration with Human Feedback: propone calibrar las probabilidades del modelo directamente con datos de preferencias usando pérdidas de margen, trabajo paralelo e independiente con ideas similares a DPO.
Tags
alineamiento DPO preferencias-humanas fine-tuning reward-model