How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model
Qué hace
Este paper hace ingeniería inversa del mecanismo computacional por el cual GPT-2 small resuelve la tarea “greater-than”: dado el prompt “The war lasted from the year 1732 to the year 17__”, el modelo debe completar con años mayores a 32 (i.e., 33–99) con probabilidad alta y con años menores o iguales a 32 con probabilidad baja. Los autores identifican el circuito mínimo responsable — un subgrafo de atención heads y capas MLP — y explican con precisión qué rol desempeña cada componente en el cómputo, distinguiendo entre los que leen el año inicial, los que implementan la comparación numérica, y los que escriben la distribución resultante a los logits.
Contexto y motivación
Los modelos de lenguaje de gran tamaño exhiben capacidades matemáticas inesperadas pese a no haber sido entrenados explícitamente para ello. Sin embargo, los estudios existentes hasta 2023 documentan estas capacidades de forma conductual — midiendo si el modelo acierta — sin explicar el mecanismo interno que las produce. Esto deja abierta una pregunta fundamental: ¿los LLMs hacen aritmética de verdad, o simplemente memorizan patrones del corpus de entrenamiento? El trabajo se ubica en la tradición de la interpretabilidad mecanística, que busca descomponer el modelo en componentes causalmente responsables de comportamientos concretos. El antecedente más directo es el análisis del circuito IOI (Wang et al., 2022), que identifica el mecanismo para la tarea de Indirect Object Identification; este paper aplica la misma metodología a una tarea numérica, con el objetivo adicional de entender si el modelo generaliza o memoriza.
Tarea estudiada
La tarea se denomina year-span prediction (predicción de rango de años). El formato de entrada es:
“The [NOUN] lasted from the year XXYY to the year XX”
donde XX es el siglo (tomado del conjunto {11, 12, 13, 14, 15, 16, 17}) e YY es el año de inicio (entre 02 y 98). El modelo debe predecir el siguiente token, que corresponde a las decenas del año final. La respuesta correcta no es un único año sino una distribución: el modelo debe asignar probabilidad más alta a los dígitos ZZ > YY que a los dígitos ZZ ≤ YY.
Ejemplo concreto: Para el input “The war lasted from the year 1732 to the year 17”, el modelo debe producir una distribución donde los tokens “33”, “34”, …, “99” tienen logits más altos que “01”, “02”, …, “32”. El comportamiento esperado es una función de probabilidad acumulada con un salto brusco justo en YY=32.
El dataset contiene 10.000 ejemplos con 120 sustantivos tomados de FrameNet. Las restricciones de tokenización excluyen años que no se tokenicen como un único token, lo que limita el rango efectivo a ciertos valores por siglo.
Métricas de evaluación:
- Probability difference: proporción de probabilidad total concentrada en años > YY. GPT-2 small alcanza 81.7% (SD: 19.3%).
- Cutoff sharpness: cuán abrupta es la transición de probabilidades alrededor de YY. Valor base: 6.0% (SD: 7.2%).
Metodología
Herramienta principal: Path Patching
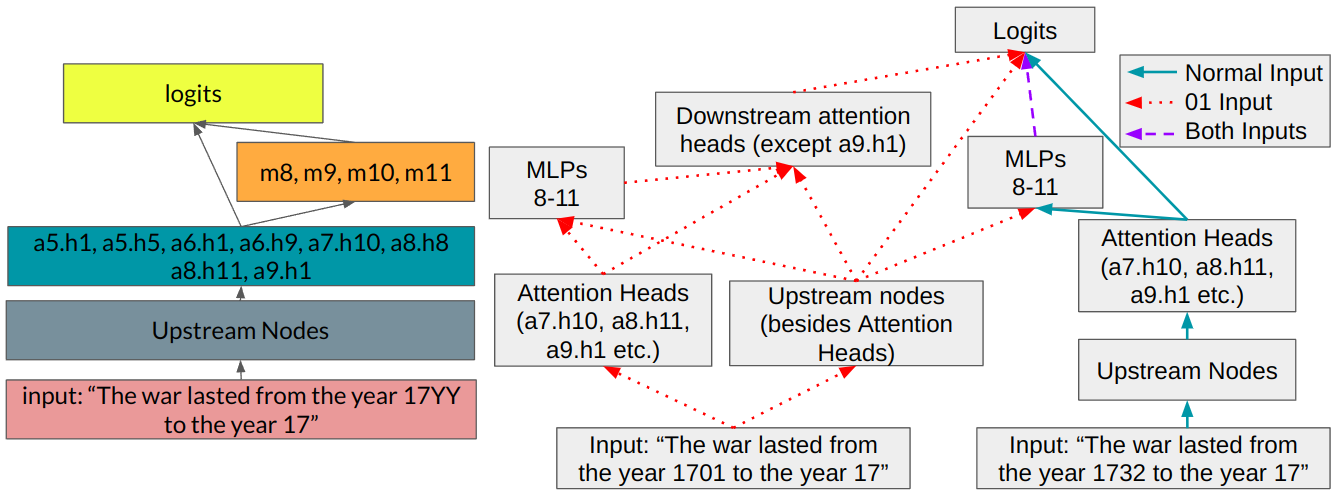
El método central es el path patching (Goldowsky-Dill et al., 2023), una generalización del activation patching que permite atribuir causalidad a ejes específicos del grafo computacional del transformer (no solo a nodos).
Formalmente, sea $M$ el modelo con entradas $(x_\text{clean}, x_\text{corrupt})$. El activation patching estándar reemplaza la activación $a_i$ del componente $i$ en la pasada limpia por su valor en la pasada corrupta:
\[\text{Impacto}(i) = \mathcal{L}(M(x_\text{clean})) - \mathcal{L}(M(x_\text{clean}, a_i \leftarrow a_i^{x_\text{corrupt}}))\]donde $\mathcal{L}$ es la métrica de comportamiento (e.g., probability difference). Un impacto alto indica que el componente $i$ es causalmente importante.
El path patching refina esto: en lugar de parchear toda la activación de un componente, parcha solo el camino específico desde el componente $i$ hasta el componente $j$, manteniendo el resto del modelo en el estado limpio. Esto evita confundir el efecto directo de un componente sobre la salida con su efecto indirecto a través de otros componentes.
Dataset corrupto (“01-dataset”): Para aumentar la señal, los autores usan como input corrupto la versión del prompt donde YY se reemplaza por “01”. Esto hace que las cabezas que normalmente elevan los años > YY eleven en cambio los años > 01, lo cual produce errores de gran magnitud y facilita la detección de componentes importantes.
Proceso iterativo de identificación del circuito
El circuito se construye de forma descendente, en tres capas:
Capa 0 — Contribuciones directas a los logits: Se parchean individualmente los 144 attention heads (12 capas × 12 cabezas) y las 12 capas MLP para medir cuáles contribuyen directamente a los logits finales. Se identifican como contribuyentes directos: MLPs 8, 9, 10, 11, y las cabezas a5.h1, a5.h5, a6.h9, a7.h10, a8.h8, a8.h11, a9.h1.
Capa 1 — Inputs a las MLPs importantes: Para cada MLP importante, se identifican qué componentes upstream contribuyen a sus activaciones. Se descubre que MLP 8 recibe inputs cruciales de MLPs 0–3 y de las cabezas a0.h1, a0.h3, a0.h5.
Capa 2 — Inputs a los attention heads: Para las cabezas identificadas, se analizan qué heads upstream son fuentes críticas de información vía composición de llaves/queries/valores (K-composition, Q-composition, V-composition).
Técnicas de análisis de roles
Una vez identificados los componentes del circuito, se analiza su función mediante:
- Logit lens: proyectar las activaciones intermedias al espacio del vocabulario (multiplicar por la matriz de embeddings transpuesta $W_U$) para inferir qué información transporta cada componente en cada posición del residual stream.
- Visualización de attention patterns: para cada head, graficar la matriz de atención $A = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)$ y determinar desde qué tokens atiende al token de output.
- Probing classifiers: regresores lineales entrenados para predecir el valor de YY desde las activaciones intermedias, con el fin de determinar en qué puntos del grafo está codificada la información numérica.
- Análisis PCA: reducción a 2D de las representaciones de input a las MLPs para visualizar si hay estructura geométrica ordenada por YY.
Componentes / Hallazgos
Attention heads: lectura y comunicación de YY
Las cabezas de atención en el circuito tienen un rol principal: leer el valor de YY desde la posición del año inicial y comunicarlo hacia las capas más profundas. Las heads a5.h1, a6.h9, a7.h10, a8.h8 muestran patrones de atención donde el token de output atiende fuertemente a la posición de YY en el input.
El análisis de logit lens sobre estas heads revela que el token YY se convierte en el token con mayor logit proyectado, lo que indica que las heads están transportando la identidad del año inicial hacia el residual stream en la posición de output.
MLPs 9–11: implementación de greater-than
Las capas MLP 9, 10 y 11 son las responsables directas de computar la comparación numérica. Su análisis mediante logit lens muestra un patrón triangular superior: para un input con YY=32, el MLP eleva los logits de los tokens “33”, “34”, …, “99” y deprime los de “01”, …, “32”. Este patrón varía coherentemente con el valor de YY, lo que confirma que estas MLPs implementan algo funcionalmente equivalente a “si YY=k, elevar todos los años > k”.
Los autores descomponen la contribución directa vs. indirecta de cada MLP a los logits:
- MLP 10: 56% contribución directa, 16% indirecta
- MLP 9: 28% directa, 32% indirecta
- MLP 8: 14% directa, 39% indirecta
MLP 11: restricción de duración máxima
Además de la comparación, MLP 11 aplica una restricción adicional: reduce las probabilidades de los años que estén más de ~50 años por encima de YY. Esto refleja el sesgo del corpus de entrenamiento, donde los eventos rara vez duran más de 50 años, y explica por qué el modelo no asigna probabilidad uniforme a todos los años > YY sino que la concentra en una ventana.
MLP 8: rol indirecto
MLP 8 muestra un patrón diagonal en el logit lens (no triangular superior), lo que sugiere que no implementa directamente la comparación sino que actúa como procesador intermedio que amplifica o refina la representación de YY antes de pasarla a las MLPs superiores.
Estructura numérica en el residual stream
El análisis PCA de las representaciones de input a MLP 10 revela que los ejemplos con distintos valores de YY se organizan en un arco circular ordenado en el plano de los dos primeros componentes principales. Esta estructura geométrica sugiere que el residual stream codifica el valor numérico de YY en una representación continua y ordenada, aunque la evidencia causal de que esta representación sea la que utilizan las MLPs es débil: ablatar las dimensiones identificadas por PCA solo degrada el rendimiento de 81.7% a 64.7%.
Ejemplo ilustrativo
Consideremos el ejemplo concreto “The treaty lasted from the year 1347 to the year 13”.
-
Token 1347 en el embedding: el token “47” tiene una representación inicial en el embedding estático que ya contiene cierta información sobre la magnitud numérica (los embeddings de años forman clusters por valor).
-
Capas 0–4: Las MLPs 0–3 procesan el contexto general. Las cabezas a0.h1, a0.h3, a0.h5 comienzan a construir representaciones del contexto “from the year 13YY to the year 13”.
-
Capas 5–8 (attention heads del circuito): Las heads a5.h1, a6.h9, a7.h10, a8.h8 atienden al token “47” desde la posición final del input. El logit lens en estas posiciones muestra que el token “47” tiene el logit proyectado más alto, indicando que las heads están escribiendo “el año es 47” en el residual stream de la posición de output.
-
MLP 9: Recibe esta representación y comienza a elevar los logits de “48”, “49”, …, “99”. El patrón ya muestra la forma triangular superior característica.
-
MLP 10 (mayor contribución directa): Amplifica el patrón. La distribución de logits ya tiene la forma de escalón: alta para años > 47, baja para años ≤ 47.
-
MLP 11: Aplica la corrección de duración — reduce las probabilidades de años en el rango 90–99 (demasiado lejanos de 47 para ser plausibles como duración de un tratado según el corpus).
-
Logits finales: La distribución resultante concentra la mayor probabilidad en los tokens “48”–”97”, con un escalón brusco en 47.
Verificación del circuito: Cuando solo se permiten los caminos del circuito (parchando el resto del modelo con el input corrupto “01”), la probability difference cae de 81.7% (modelo completo) a 72.7%, una recuperación del 89.5% del comportamiento. La prueba de necesidad (parchando solo el circuito con el input corrupto) produce una probability difference de -36.6%, confirmando que el circuito es causalmente necesario.
Resultados principales
- Rendimiento del circuito completo: probability difference de 72.7% (89.5% de recuperación del baseline del modelo completo de 81.7%).
- Cutoff sharpness del circuito: 8% (mejora respecto al baseline de 6%).
- Prueba de necesidad: al corromper solo el circuito, probability difference cae a -36.6%.
- Contribución de MLP 10: mayor contribuyente directo con 56% de contribución directa a los logits.
- Generalización: el circuito recupera ≥69% del rendimiento en variantes de la tarea como “The [noun] started in the year 17YY and ended in the year 17” (98.8% de recuperación) y secuencias numéricas como “1599, 1607, …, 17YY, 17” (90.3%).
- Fallo en overgeneralización: el circuito se activa inapropiadamente para “The [noun] ended in the year 17YY and started in the year 17” (donde se requiere less-than, no greater-than), alcanzando 90%+ de recuperación del comportamiento incorrecto.
- Nivel neuronal: en MLP 10, las top-100 neuronas individuales aproximan bien la salida completa de la capa, pero ninguna neurona individual produce el patrón triangular superior por sí sola — el cómputo es distribuido.
- Representaciones PCA: ablatar las dimensiones asociadas al valor de YY en el residual stream solo degrada el rendimiento de 81.7% a 64.7%, sugiriendo que la representación lineal de YY no es el único canal de información.
Ventajas respecto a trabajos anteriores
- Primer análisis mecanístico completo de una capacidad numérica en un LLM preentrenado: los trabajos anteriores (Nanda et al., 2023 sobre grokking) estudiaban modelos entrenados desde cero en tareas aritméticas, no modelos de lenguaje preentrenados.
- Distinción roles attention vs. MLP: el paper clarifica empíricamente que las attention heads actúan como “lectores” (recuperan YY) mientras que las MLPs actúan como “computadores” (implementan la comparación), lo cual era una hipótesis en trabajos anteriores pero no había sido demostrada causalmente.
- Evidencia del rol de las MLPs como memorias de conocimiento numérico: el patrón triangular superior en las MLPs demuestra que estas capas han internalizado durante el preentrenamiento representaciones de relaciones de orden entre números, consistente con la hipótesis de Geva et al. (2021) pero ahora con evidencia causal directa.
- Análisis de generalización vs. memorización: el paper va más allá de la descripción del circuito para testear activamente si el mecanismo generaliza a variantes de la tarea, revelando tanto la robustez (same-structure tasks) como los límites (opposite comparison) del circuito.
- Metodología exportable: el proceso de identificación iterativa del circuito con path patching en tres capas (logits → MLPs intermedias → heads) es una plantilla metodológica que puede aplicarse a otras tareas.
Trabajos previos relacionados
Este trabajo se ubica en la intersección de la interpretabilidad mecanística y el razonamiento matemático en LLMs. Utiliza herramientas de análisis de circuitos previamente desarrolladas para estudiar cómo emergen capacidades numéricas en modelos preentrenados.
- Elhage et al. (2021) — A Mathematical Framework for Transformer Circuits: proporciona el marco formal de circuitos en transformers (residual stream, composición de cabezas) sobre el que se construye todo el análisis del paper.
- Wang et al. (2022) — Interpretability in the Wild: IOI Circuit: referencia metodológica directa; el circuito IOI en GPT-2 small es el antecedente más cercano en cuanto a análisis de circuitos completos en modelos preentrenados.
- Goldowsky-Dill et al. (2023) — Localizing Model Behavior with Path Patching: introduce el path patching que se usa directamente en este paper para atribuir causalidad a los componentes del circuito.
- Geva et al. (2021) — Transformer Feed-Forward Layers are Key-Value Memories: aporta la interpretación de las capas MLP como memorias clave-valor, que el paper extiende al dominio numérico.
- Meng et al. (2022) — Locating and Editing Factual Associations in GPT: demuestra que el conocimiento factual se localiza en las capas FFN, motivando la búsqueda de representaciones numéricas en las MLP del circuito.
- Vig et al. (2020) — Investigating Gender Bias with Causal Mediation Analysis: introduce el análisis de mediación causal para atribuir comportamientos a componentes del transformer, técnica adaptada en este paper.
- Geiger et al. (2021) — Causal Abstractions of Neural Networks: proporciona el marco de intervenciones causales que fundamenta las ablaciones causales del paper.
- Nanda et al. (2023) — Progress Measures for Grokking via Mechanistic Interpretability: muestra cómo el análisis de circuitos puede explicar la adquisición de capacidades matemáticas en modelos entrenados desde cero, contexto complementario al estudio de modelos preentrenados.
- Olah et al. (2020) — Zoom In: An Introduction to Circuits: trabajo fundacional de la perspectiva de circuitos en redes neuronales que inspira la metodología general del paper.
- Brown et al. (2020) — Language Models are Few-Shot Learners: establece que los LLMs adquieren capacidades matemáticas sin entrenamiento explícito, motivando la pregunta central del paper sobre cómo ocurre esto internamente.
Tags
interpretabilidad-mecanística circuitos GPT-2 razonamiento-numérico MLP-layers