D-CALM: A Dynamic Clustering-based Active Learning Approach for Mitigating Bias
Qué hace
Propone D-CALM, un método de aprendizaje activo para debiasing que selecciona dinámicamente los ejemplos más informativos para anotar y usar en el fine-tuning de debiasing. El objetivo es reducir el sesgo con el mínimo de datos anotados, usando clustering para maximizar la diversidad.
Metodología
El problema con los métodos de debiasing basados en fine-tuning es que requieren grandes cantidades de datos anotados para ser efectivos. Anotar datos de sesgo es costoso: requiere anotadores especializados que entiendan los matices del sesgo social.
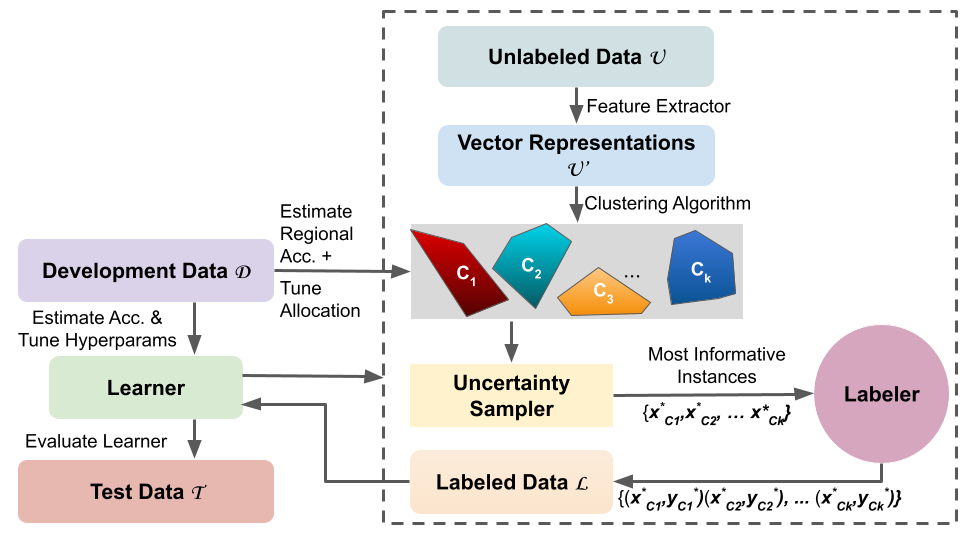
La solución: Active Learning para debiasing. En lugar de anotar un dataset grande al azar, se seleccionan iterativamente los ejemplos más “informativos” para el modelo actual:
El proceso D-CALM:
- Clustering inicial: Se representan los candidatos de datos (textos sin anotar) en el espacio de embeddings del modelo y se agrupan con k-means.
- Selección activa: En cada iteración, se selecciona el ejemplo de cada cluster que está más cerca del centroide (más representativo de su cluster) Y que el modelo actual clasifica con mayor incertidumbre respecto al sesgo.
- Anotación y fine-tuning: Los ejemplos seleccionados se anotan (¿sesgado o no sesgado?) y se usan para fine-tunear el modelo.
- Actualización dinámica: Los clusters se recalculan periódicamente a medida que el modelo mejora.
Las capas modificadas son las capas de atención y FFN de BERT mediante fine-tuning estándar sobre los datos anotados activamente.
Datasets utilizados
- CrowS-Pairs: pares de frases sesgadas/no sesgadas como pool de candidatos.
- WinoBias: evaluación de sesgo de género.
- Custom diverse bias pool: corpus de textos de múltiples fuentes como pool de anotación.
Ejemplo ilustrativo
D-CALM tiene acceso a 10.000 textos no anotados que potencialmente contienen sesgo. En lugar de anotar todos, en la primera iteración selecciona 50 textos: uno por cluster que el modelo actual clasifica con ~50% de confianza de contener sesgo (máxima incertidumbre). Después de anotar estos 50 y hacer fine-tuning, el modelo mejora. En la segunda iteración, los clusters cambian y se seleccionan otros 50 textos informativos. Después de 10 iteraciones (500 ejemplos anotados), el modelo logra un rendimiento comparable al fine-tuning con los 10.000 ejemplos.
Resultados principales
- D-CALM logra resultados de debiasing comparables al fine-tuning completo usando sólo 20-30% de los datos.
- La diversidad garantizada por el clustering previene que el modelo se sobreajuste a patrones específicos de sesgo.
- Supera a otras estrategias de active learning (random sampling, uncertainty-only) en el mismo número de ejemplos anotados.
- La dinámica de los clusters (actualización periódica) es clave: los clusters estáticos son 10-15% menos eficientes.
Ventajas respecto a trabajos anteriores
- Primera aplicación de active learning dinámico específicamente para debiasing.
- Reduce dramáticamente el costo de anotación, haciendo el debiasing más práctico.
- El clustering garantiza diversidad en los ejemplos seleccionados, evitando el sobreajuste a patrones específicos.
Trabajos previos relacionados
El paper se sitúa en la intersección entre el aprendizaje activo (active learning) y la mitigación de sesgo en NLP. La sección de trabajos relacionados se organiza en torno a enfoques de AL con y sin clustering, y al sesgo en clasificadores de texto.
- Settles (2009) — Active learning literature survey: referencia fundacional del aprendizaje activo que define los escenarios y estrategias de consulta base sobre las que D-CALM se construye.
- Yuan et al. (2020) — Cold-start active learning through self-supervised language modeling: trabajo reciente de AL en NLP que identifica la susceptibilidad al sesgo de los métodos de AL para redes neuronales, motivando directamente D-CALM.
- Farquhar et al. (2021) — Mitigating bias in AL with corrective weights: propone pesos correctivos para mitigar sesgo en AL; D-CALM ofrece una alternativa más sencilla de aplicar en el contexto NLP.
- Gudovskiy et al. (2020) — Self-supervised Fischer-Kernel for AL on biased datasets: método de AL para datasets sesgados que requiere profundo conocimiento de ML; D-CALM es más accesible para la comunidad NLP.
- Bodó et al. (2011) y Berardo et al. (2015) — Active learning with static clustering: métodos de AL basados en clustering estático que D-CALM supera al actualizar dinámicamente los clusters en cada iteración.
- Davidson et al. (2019) — Racial bias in hate speech detection datasets: establece que el sesgo del clasificador puede derivar de distribuciones desequilibradas en los datos de entrenamiento, motivación central de D-CALM.
- Devlin et al. (2019) — BERT: modelo base (bert-base-cased) sobre el que se aplica D-CALM en los experimentos principales.
- Reimers & Gurevych (2019) — SentenceBERT: se usa para obtener representaciones vectoriales de los textos antes de aplicar el clustering en el framework de D-CALM.
- Ahn & Oh (2021) — Mitigating language-dependent ethnic bias in BERT: trabajo relacionado que aborda el sesgo étnico en modelos de lenguaje, parte del contexto de sesgo en clasificadores NLP que motiva D-CALM.
Tags
debiasing active-learning clustering eficiencia-datos BERT