Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes
Qué hace
Propone Self-Debiasing: un enfoque de zero-shot que usa el propio LLM para reconocer y corregir sus sesgos durante la generación, sin ningún entrenamiento adicional ni modificación de pesos. Funciona puramente mediante prompting.
Metodología
La premisa es que los LLMs modernos tienen suficiente conocimiento sobre sesgos sociales como para reconocerlos y corregirlos si se les pide explícitamente. El proceso tiene dos pasos en cada respuesta:
Paso 1 — Reconocimiento (Self-Recognition): Antes de generar la respuesta final, se le pide al modelo que evalúe si una respuesta inicial podría contener estereotipos. El prompt tiene el formato:
- “Genera una respuesta inicial a: [PREGUNTA]”
- “Ahora evalúa: ¿contiene esta respuesta estereotipos o sesgos sobre algún grupo? ¿Cuáles?”
Paso 2 — Corrección (Self-Refinement): Si el modelo identifica sesgos en su respuesta inicial, se le pide que genere una versión mejorada:
- “Reescribe la respuesta eliminando los sesgos identificados, manteniendo la misma información útil.”
La respuesta final es la versión refinada. Los pesos del modelo no se tocan en ningún momento.
Variantes exploradas:
- Zero-shot: sin ejemplos adicionales.
- Few-shot: con ejemplos de reconocimiento y corrección de sesgo en el prompt.
- Chain-of-thought: pidiendo al modelo que razone paso a paso sobre los sesgos.
Datasets utilizados
- BBQ: preguntas con contexto ambiguo.
- StereoSet: completación de oraciones.
- WinoBias: correferencias de género.
- BOLD: generación de texto sobre grupos demográficos.
- Evaluado en GPT-4, GPT-3.5, Llama-2 (7B, 13B, 70B), Mistral.
Ejemplo ilustrativo
Sin Self-Debiasing: “Necesito contratar un asistente de vuelo ¿qué características son importantes?” → el modelo lista características y usa implícitamente el pronombre femenino.
Con Self-Debiasing:
- Paso 1: genera respuesta con pronombre femenino.
- Paso 1b: identifica el sesgo: “Esta respuesta usa pronombre femenino implícitamente asumiendo que los asistentes de vuelo son mujeres.”
- Paso 2: genera respuesta corregida usando pronombres neutros o balanceados.
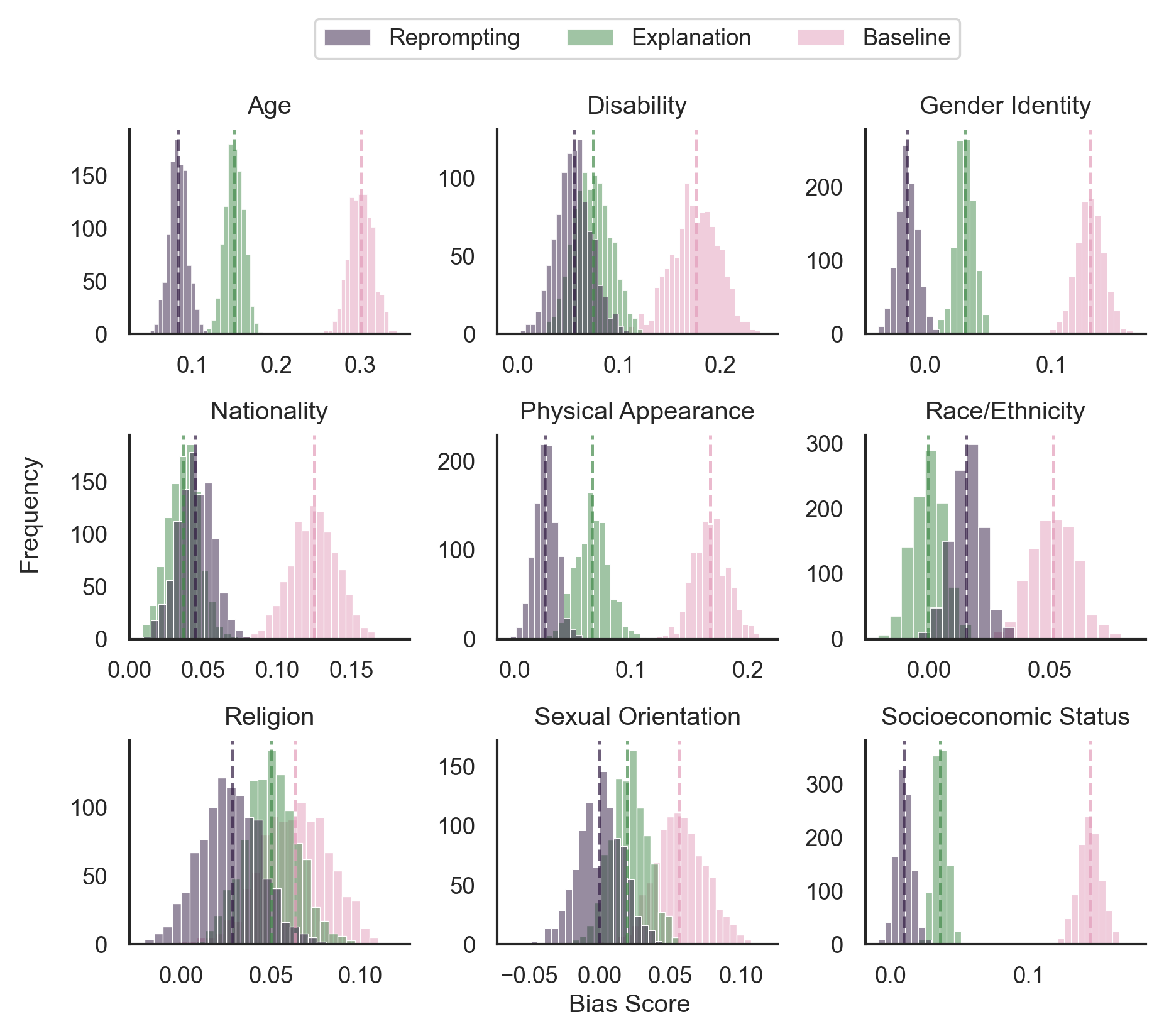
Resultados principales
- En BBQ, Self-Debiasing reduce el sesgo en un 20-40% en modelos grandes (GPT-4, Llama-70B).
- El efecto es menor en modelos pequeños (Llama-7B): no tienen suficiente capacidad meta-cognitiva.
- La versión few-shot es más efectiva que zero-shot.
- No hay degradación en utilidad: las respuestas debiased son igual de informativas.
- Limitación: sólo funciona con sesgos que el modelo “conoce” — sesgos sutiles o implícitos pueden no ser reconocidos.
Ventajas respecto a trabajos anteriores
- Zero-shot: no requiere entrenamiento, datos adicionales, ni modificación del modelo.
- Aplicable a cualquier LLM con capacidades de razonamiento suficientes.
- La reflexividad (usar el modelo para corregirse a sí mismo) es un enfoque novedoso y escalable.
Trabajos previos relacionados
El paper organiza la literatura de mitigación de sesgo en cuatro categorías metodológicas: (1) técnicas basadas en datos aumentados, (2) fine-tuning adicional, (3) modificación de algoritmos de decoding, y (4) modelos auxiliares de post-procesamiento. El trabajo de Gallegos et al. se posiciona en contraste con todas estas categorías al proponer una aproximación zero-shot que no requiere ninguno de esos recursos.
- Schick et al. (2021) — Self-Debias (white-box): acuñó el término “self-debiasing” al demostrar que los LLMs pueden autodiagnosticar sesgos; sin embargo, usa un algoritmo de decoding modificado (caja blanca), mientras que Gallegos et al. proponen una variante de caja negra vía prompting puro.
- Parrish et al. (2022) — BBQ: A Hand-Built Bias Benchmark: dataset principal de evaluación; el benchmark de preguntas de opción múltiple con contexto ambiguo permite medir directamente cuándo el modelo usa estereotipos para responder.
- Webster et al. (2020) — Dropout como debiasing: representa la familia de técnicas de pre-entrenamiento adicional que requieren acceso a los parámetros del modelo; contraejemplo metodológico para la propuesta zero-shot.
- Zmigrod et al. (2019) — CDA: representa la familia de técnicas de augmentación de datos de entrenamiento; requiere reentrenamiento, lo que lo hace inviable para modelos de caja negra.
- Meade et al. (2022) — An Empirical Survey of Debiasing Techniques: proporciona el panorama de métodos existentes y sus limitaciones de escalabilidad; motiva directamente la búsqueda de alternativas zero-shot.
- He et al. (2022) — MABEL: ejemplo de fine-tuning adicional para debiasing de género mediante contrastive learning; eficaz pero requiere acceso a parámetros del modelo.
- Mattern et al. (2022) — Debiasing via Prompt Abstraction: examina cómo el nivel de abstracción en los prompts de debiasing afecta las salidas del LLM, pero solo para sesgos de ocupación y género; el trabajo de Gallegos et al. lo extiende a nueve grupos sociales.
- Brown et al. (2020) — GPT-3 / few-shot learning: establece la capacidad de few-shot y zero-shot de los LLMs que hace posible el self-debiasing; es la referencia metodológica fundamental del paper.
- Wei et al. (2022) — Chain-of-Thought Prompting: demuestra que pedir al modelo que razone paso a paso mejora capacidades de razonamiento; inspira el enfoque de pedir al modelo que explique las suposiciones inválidas antes de responder.
- Bender et al. (2021) — Stochastic Parrots: motivación del paper; documenta que los LLMs aprenden y amplifican sesgos dañinos del texto de entrenamiento.
Tags
debiasing zero-shot prompting sin-entrenamiento LLM