Making AI Forget You: Data Deletion in Machine Learning
Qué hace
Extiende el concepto de machine unlearning —que había sido propuesto solo para clasificadores discretos— a algoritmos de aprendizaje con datos continuos, con foco especial en k-means clustering. El paper formaliza qué significa que un algoritmo de machine learning “olvide” un dato, propone la noción de algoritmo de borrado (deletion algorithm) y demuestra que el unlearning exacto y eficiente es posible para k-means, un algoritmo fundamental del aprendizaje no supervisado.
Introduce además la distinción entre exact unlearning (la distribución de salida es exactamente la misma que si nunca se hubiera entrenado con el dato) y approximate unlearning (la distribución es estadísticamente cercana), estableciendo el marco teórico que los trabajos posteriores adoptan.
Metodología
El paper define formalmente un algoritmo de borrado para un modelo de ML:
Dado un modelo M entrenado con dataset D, un algoritmo de borrado A recibe (M, D, x) donde x es el punto a borrar, y produce un modelo M’ tal que la distribución de M’ es indistinguible (o cercana) a la distribución del modelo que habría resultado de entrenar con D \ {x} desde cero.
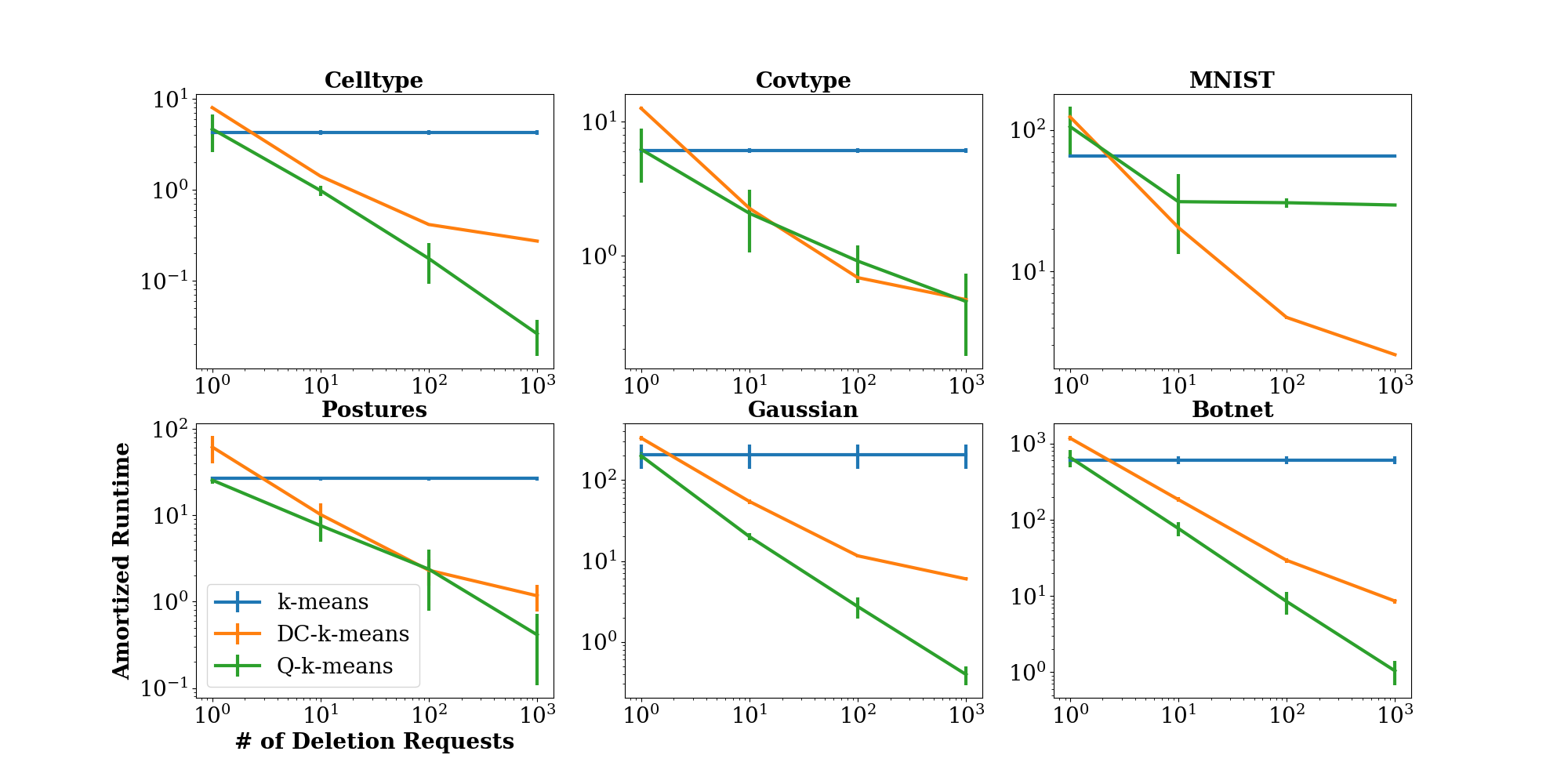
Para k-means, el paper propone dos tipos de algoritmos de borrado:
-
Borrado exacto con reentrenamiento parcial: Aprovecha la estructura incremental de k-means. Al borrar un punto x, solo es necesario considerar el centroide al que pertenecía x. Si x no era el único punto en su cluster, el centroide se actualiza con una fórmula de media incremental O(1). Si era el único punto, se requiere un reentrenamiento más costoso.
-
Borrado con proyección estocástica: Para el caso difícil, el paper propone añadir ruido gaussiano al centroide modificado para que la distribución sea exactamente la del reentrenamiento desde cero (bajo ciertas condiciones de regularidad).
El paper también demuestra cotas de complejidad: el número esperado de borrados que requieren reentrenamiento completo es sublineal en el tamaño del dataset.
Datasets utilizados
- Datasets sintéticos de clustering gaussiano (para análisis teórico).
- MNIST: Para demostrar unlearning en k-means sobre datos reales de imagen.
- Adult dataset (UCI): Para experimentos de borrado en clustering sobre datos tabulares.
Ejemplo ilustrativo
Un servicio médico agrupa pacientes con k-means (k=10 grupos) para personalizar tratamientos. Un paciente solicita que sus datos sean borrados del sistema. Sin el algoritmo de Ginart et al., habría que reejecutar k-means sobre los N-1 pacientes restantes (~horas de cómputo). Con el algoritmo de borrado exacto: el paciente pertenecía al cluster 7 con 847 otros pacientes. El centroide del cluster 7 se recalcula en O(d) tiempo simplemente ajustando la media: si el paciente tenía valores {edad: 45, colesterol: 200}, el nuevo centroide del cluster 7 es la media de los 846 pacientes restantes. El borrado tarda microsegundos.
Resultados principales
- Para k-means, el costo amortizado de borrado es O(1) en esperanza para la mayoría de solicitudes, con reentrenamiento completo solo cuando se elimina el último punto de un cluster.
- El unlearning exacto es posible sin modificar el proceso de entrenamiento original.
- Las cotas demuestran que el número de puntos que causan reentrenamiento completo es O(k log n) en n solicitudes de borrado.
- Los experimentos muestran que el modelo después del borrado es estadísticamente indistinguible del reentrenado desde cero.
Ventajas respecto a trabajos anteriores
- Cao & Yang (2015) solo tratan clasificadores que se descomponen como sumas de componentes (modelos de estadísticas suficientes). Ginart et al. extienden el unlearning a k-means, que no tiene esa estructura.
- Es el primer trabajo en formalizar el unlearning para aprendizaje no supervisado (clustering).
- Introduce la distinción terminológica entre exact y approximate unlearning que se convierte en estándar en el campo.
- Demuestra que el unlearning eficiente no siempre requiere modificar el proceso de entrenamiento (como SISA), sino que puede ser post-hoc si se aprovecha la estructura del algoritmo.
Trabajos previos relacionados
- Cao & Yang (2015) — Towards Making Systems Forget with Machine Unlearning: trabajo fundacional del machine unlearning; Ginart et al. son la primera extensión a modelos no descomponibles y datos continuos.
- Bourtoule et al. (2021) — Machine Unlearning via SISA: cita a Ginart et al. como la formalización de la condición de indistinguibilidad estadística que SISA adopta.
- Dwork et al. (2006) — Differential Privacy: el ruido estocástico usado en los algoritmos de borrado de Ginart et al. es análogo al mecanismo gaussiano de la privacidad diferencial.
Tags
machine-unlearning exact-unlearning k-means datos-continuos privacidad clustering