Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Qué hace
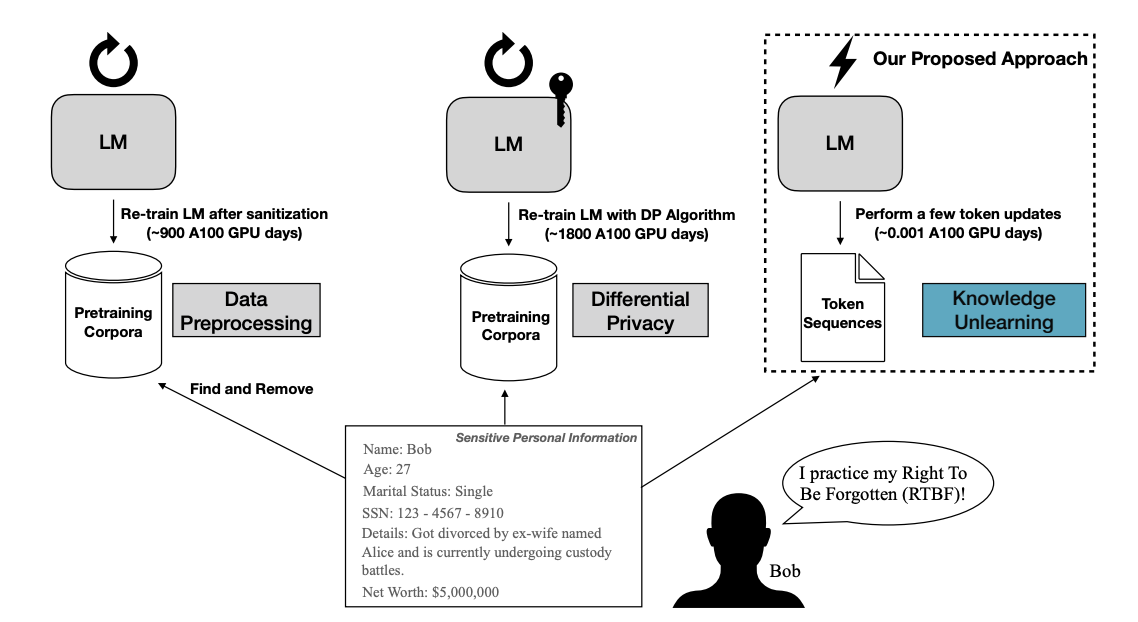
Propone aplicar machine unlearning a modelos de lenguaje (LMs) para eliminar información privada o sensible que fue memorizada durante el entrenamiento. El método consiste en aplicar ascenso de gradiente sobre los ejemplos que se desea olvidar.
Metodología
El entrenamiento estándar de un LM minimiza la pérdida (loss) sobre los datos de entrenamiento. El truco del unlearning es simple pero poderoso: en lugar de minimizar la pérdida sobre los datos a olvidar, se maximiza (ascenso de gradiente). Esto empuja al modelo a asignar menor probabilidad a esos textos, “desaprendiendo” las asociaciones.
Los parámetros modificados son todos los pesos del modelo (capas de atención, FFN, embeddings), ya que se realiza una actualización estándar de backpropagation pero con el signo del gradiente invertido.
El desafío principal es evitar el “olvido catastrófico generalizado”: si aplicamos ascenso de gradiente sin restricciones, el modelo puede degradarse y perder capacidades generales. Para mitigarlo, el entrenamiento alterna entre:
- Ascenso de gradiente sobre el forget set (datos a olvidar).
- Descenso de gradiente normal sobre un retain set (datos generales de referencia, como C4 o una muestra aleatoria del Pile).
Datasets utilizados
- The Pile: corpus masivo de texto usado para entrenar LMs; se seleccionan subconjuntos con información privada simulada.
- Datos privados sintéticos: secuencias que contienen nombres, emails, números de teléfono y otra información personal identificable (PII).
- Evaluación de memorización: se miden ataques de extracción donde se le pide al modelo completar texto que contenía información privada.
Ejemplo ilustrativo
Supongamos que un LM fue entrenado con millones de documentos, incluyendo un email filtrado que decía: “El teléfono de Juan García es 0341-555-1234”. Si alguien le pregunta al modelo “¿Cuál es el teléfono de Juan García?”, el modelo podría responder correctamente — una violación de privacidad grave. El knowledge unlearning aplica ascenso de gradiente sobre este texto específico, de modo que el modelo ya no lo memorice y no pueda reproducirlo.
Resultados principales
- El método reduce significativamente las tasas de extracción exitosa de información privada (de ~40% a menos del 5% en algunos casos).
- Mantiene la perplejidad general (calidad del modelo) con un impacto mínimo si se usa un retain set adecuado.
- Es más rápido que el reentrenamiento completo: sólo requiere pocas épocas sobre el forget set.
- No garantiza olvido perfecto — ataques de extracción más sofisticados aún pueden recuperar parte de la información.
Ventajas respecto a trabajos anteriores
- Primer trabajo que aplica machine unlearning específicamente a LMs de forma sistemática.
- Demuestra que el ascenso de gradiente es una alternativa viable al reentrenamiento completo para eliminar conocimiento privado.
- Establece un protocolo de evaluación basado en ataques de extracción, que se convierte en estándar para trabajos posteriores.
Trabajos previos relacionados
El paper organiza los trabajos previos en tres grandes líneas: métodos de privacidad para LMs (pre/post-procesamiento de datos y privacidad diferencial), machine unlearning en modelos no-LM, y memorización en LMs. El trabajo más cercano de nuestra colección es el fundacional de Cao & Yang, citado como el origen del concepto.
- Cao & Yang (2015) — Towards Making Systems Forget with Machine Unlearning: trabajo fundacional que introduce el concepto de machine unlearning; Jang et al. lo citan como la referencia que motivó explorar el unlearning en LMs, aunque su alcance original era modelos de clasificación.
- Carlini et al. (2021) — Extracting Training Data from Large Language Models: demuestra empíricamente que los LMs pueden ser atacados para extraer datos de entrenamiento verbatim, incluyendo PII; constituye la principal motivación del problema que este paper aborda.
- Carlini et al. (2022) — Quantifying Memorization Across Neural Language Models: muestra que la extracción de datos se vuelve más fácil conforme escalan los LMs; refuerza la urgencia de soluciones post-hoc como el knowledge unlearning.
- Dwork et al. (2006) / Abadi et al. (2016) — Differential Privacy / Deep Learning with Differential Privacy: la privacidad diferencial es el principal enfoque alternativo al unlearning; el paper compara su método contra DP-Decoding y muestra ventajas de knowledge unlearning en escenarios de RTBF.
- Kandpal et al. (2022) — Deduplicating Training Data Makes Language Models Less Memorizable: propone deduplicar el corpus de preentrenamiento como forma de reducir memorización; es el método de preprocesamiento de datos con el que se compara directamente knowledge unlearning.
- Bourtoule et al. (2021) — Machine Unlearning via SISA: propone el reentrenamiento eficiente por shards como alternativa de unlearning en clasificadores; citado para contrastar con el enfoque post-hoc de este paper, que no requiere re-entrenamiento.
- Ginart et al. (2019) — Making AI Forget You: extiende machine unlearning a modelos de k-means y datos continuos; junto con Cao & Yang forma la base del área de machine unlearning citada como antecedente.
- Jagielski et al. (2022) — Measuring Forgetting of Memorized Training Examples: analiza el olvido pasivo durante el entrenamiento como forma relajada de privacidad diferencial; el paper de Jang et al. contrasta su enfoque activo (gradient ascent) con el olvido pasivo de este trabajo.
- Tirumala et al. (2022) — Memorization Without Overfitting: propone la métrica Memorization Accuracy (MA) para cuantificar cuánto ha memorizado un LM sus datos de entrenamiento; Jang et al. la adoptan directamente como una de sus métricas de evaluación.
Tags
machine-unlearning privacidad LLM gradient-ascent memorización