Unlearning Bias in Language Models by Partitioning Gradients
Qué hace
Propone PCGU (Partitioned Contrastive Gradient Unlearning), un método de caja gris para eliminar el sesgo social de modelos de lenguaje enmascarados (como BERT) identificando y actualizando solo los pesos del modelo que más contribuyen a un dominio específico de sesgo. En lugar de aplicar el debiasing de forma global sobre todos los parámetros, PCGU localiza los pesos más “responsables” del sesgo y los actualiza de forma quirúrgica.
El método es de bajo costo computacional y, aunque se entrena solo sobre el dominio de sesgo género-profesión, los experimentos muestran que produce mejoras en otros dominios de sesgo como raza y religión.
Metodología
PCGU opera en dos fases:
Fase 1 — Partición de gradientes (identificación de pesos sesgados): Se construyen pares de frases contrastivas donde el único cambio es el atributo protegido: por ejemplo, “The nurse helped him” vs. “The nurse helped her”. Se calcula el gradiente de la pérdida del modelo (en una tarea de MLM o clasificación) respecto a cada peso para cada par. Los pesos con gradientes consistentemente grandes a través de los pares contrastivos son los más “responsables” del sesgo y se seleccionan como la subred objetivo. El resto de pesos se “congelan” mediante una máscara de gradiente.
Fase 2 — Unlearning contrastivo: Se aplica un entrenamiento contrastivo solo sobre los pesos seleccionados, con el objetivo de que el modelo asigne probabilidades similares a frases que solo difieren en el atributo protegido. El entrenamiento usa un margen de pérdida contrastiva que penaliza las predicciones asimétricas entre los pares.
El método no requiere acceso a los logits internos del modelo (solo al gradiente), por eso es “caja gris” en lugar de caja blanca.
Datasets utilizados
- WinoBias: Para medir sesgo de género en co-referencia (evaluación).
- StereoSet: Para medir sesgo estereotipado en múltiples dominios (evaluación).
- CrowS-Pairs: Para medir sesgo social en frases mínimamente diferentes (evaluación).
- Pares contrastivos de género-profesión: Dataset interno construido a partir de plantillas con pares de frases género-neutrales.
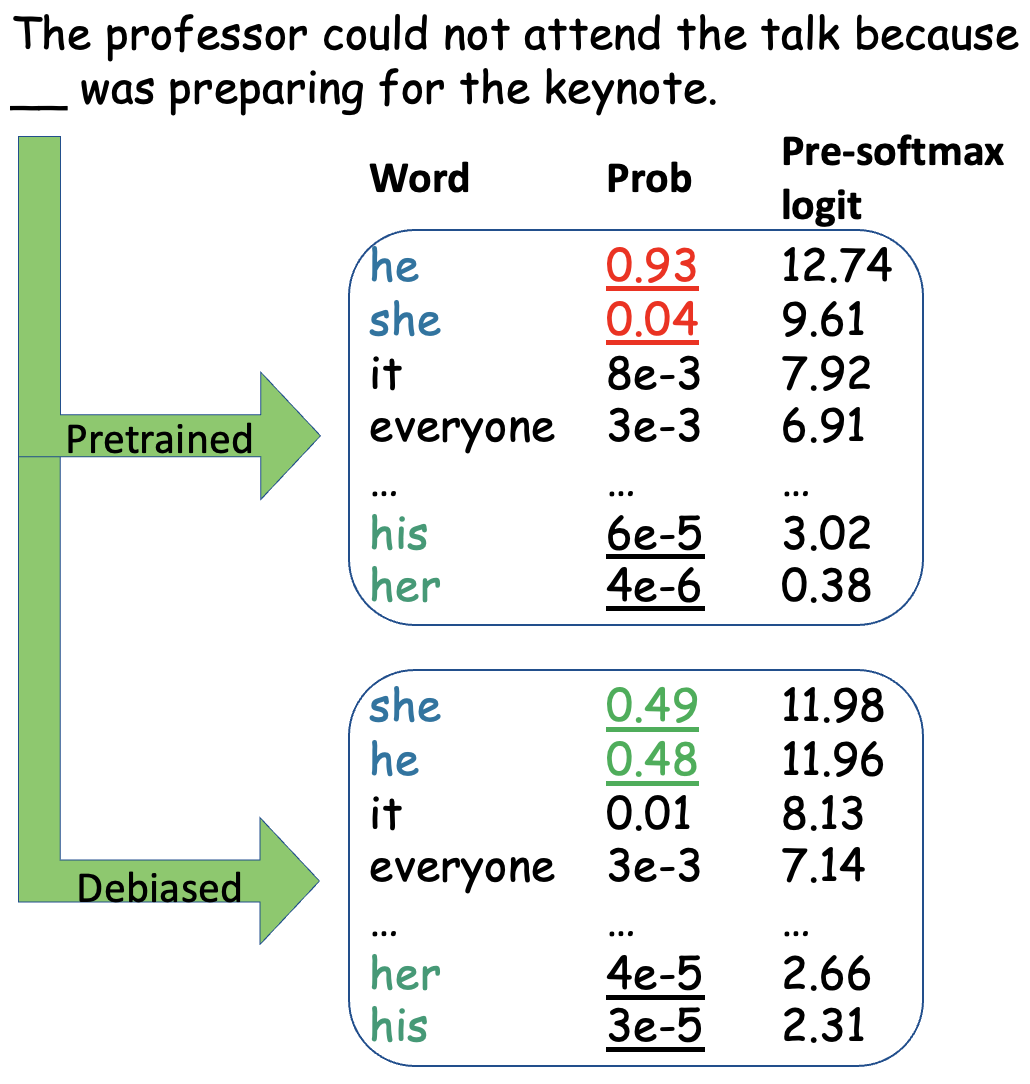
Ejemplo ilustrativo
El modelo BERT sin debiasing asigna una probabilidad mucho mayor a “The CEO hired [him]” que a “The CEO hired [her]”. PCGU calcula el gradiente de esta diferencia de probabilidades respecto a los pesos del modelo. Los 10% de pesos con mayor gradiente contrastivo medio (concentrados principalmente en las capas de atención de las últimas capas) se seleccionan. Luego se entrena solo esos pesos con ejemplos contrastivos hasta que el modelo asigna probabilidades similares a ambas frases. El resultado: el sesgo de género-profesión se reduce significativamente mientras el resto de las capacidades del modelo se preservan.
Resultados principales
- PCGU reduce el sesgo de género en WinoBias en un 15-20% relativo respecto a la línea base de BERT sin debiasing.
- Al entrenar solo en el dominio género-profesión, PCGU produce reducciones parciales de sesgo en otros dominios (raza, religión) — sugiriendo transferencia de debiasing.
- La degradación en tareas downstream (GLUE) es menor que la de métodos de debiasing global como CDA (Counterfactual Data Augmentation).
- PCGU localiza los pesos sesgados principalmente en las capas de atención más profundas y en las capas FFN intermedias.
Ventajas respecto a trabajos anteriores
- A diferencia del debiasing global (CDA, INLP), PCGU solo modifica un pequeño subconjunto de pesos, preservando mejor las capacidades generales del modelo.
- A diferencia de los métodos de proyección de subespacio (INLP, SentenceDebias), no requiere una representación geométrica explícita del sesgo.
- Es el primer método que aplica el paradigma de machine unlearning (identificar y borrar selectivamente) al problema de sesgo social en LMs.
- Produce transferencia de debiasing a dominios no entrenados, lo que sugiere que los pesos identificados capturan características generales de sesgo.
Trabajos previos relacionados
El paper organiza los trabajos previos en dos grupos: métodos de debiasing que modifican representaciones (pre o post entrenamiento) y métodos que modifican el proceso de entrenamiento.
- Bolukbasi et al. (2016) — Man is to Computer Programmer as Woman is to Homemaker: trabajo fundacional de debiasing por proyección de subespacio en embeddings estáticos; PCGU no requiere identificar geométricamente el subespacio de sesgo.
- Ravfogel et al. (2020) — INLP: elimina iterativamente el componente lineal del atributo protegido; PCGU es más eficiente al operar solo sobre pesos seleccionados.
- Lauscher et al. (2021) — Sustainable Modular Debiasing: usa adaptadores para debiasing modular; PCGU es más ligero al no añadir parámetros nuevos.
- Meade et al. (2021) — An Empirical Survey of Debiasing Techniques: evaluación comparativa de métodos de debiasing; PCGU es evaluado sobre los mismos benchmarks.
- Dige et al. (2024) — Can Machine Unlearning Reduce Social Bias?: evalúa PCGU como uno de los dos métodos principales de unlearning para debiasing.
Tags
debiasing machine-unlearning gradiente sesgo-implícito masked-language-model partición-de-pesos