Can Machine Unlearning Reduce Social Bias in Language Models?
Qué hace
Explora si los métodos de machine unlearning diseñados para privacidad/copyright pueden aplicarse para reducir sesgos sociales (género, raza) en LLMs, usando el “unlearning” de asociaciones estereotipadas como alternativa a los métodos de debiasing tradicionales.
Metodología
La idea central es tratar los ejemplos biaseados del corpus de entrenamiento como el “forget set”. Si el modelo “desaprende” las frases que contienen estereotipos (ej. “los médicos son hombres”, “las enfermeras son mujeres”), los sesgos deberían reducirse.
El proceso:
- Identificación del forget set de sesgo: Se seleccionan frases del corpus de entrenamiento que contienen asociaciones estereotipadas explícitas (usando clasificadores de sesgo y bases de datos como StereoSet y CrowS-Pairs).
- Aplicación de métodos de unlearning: Se prueban gradient ascent, gradient difference, y EWC (Elastic Weight Consolidation) sobre el forget set de sesgo.
- Evaluación: Se mide el sesgo residual en StereoSet, WinoBias, CrowS-Pairs y BOLD, comparando con el modelo original y con métodos de debiasing tradicionales.
Las partes del modelo modificadas son todos los parámetros a través de fine-tuning estándar, ya que los métodos de unlearning no son quirúrgicos.
Datasets utilizados
- StereoSet: frases con completaciones estereotipadas vs. anti-estereotipadas.
- WinoBias: resolución de correferencias con sesgos de género en ocupaciones.
- CrowS-Pairs: pares de frases con/sin estereotipo de raza, género, religión.
- BOLD: evaluación de sentimiento en texto generado sobre grupos demográficos.
- Forget set de sesgo: subconjunto identificado del corpus de entrenamiento.
Ejemplo ilustrativo
Una frase típica en el forget set podría ser: “El cirujano habló con su asistente; ella tomó notas cuidadosamente.” Aquí, el pronombre “ella” implica que el asistente (no el cirujano) es femenino — un estereotipo de género en ocupaciones médicas. El método de unlearning aplica gradient ascent sobre estas frases para que el modelo “desaprenda” estas asociaciones. Después del unlearning, cuando el modelo ve “El cirujano habló con su asistente”, debería ser igual de probable que use “él” o “ella” para cualquiera de los dos roles.
Resultados principales
- Los métodos de unlearning reducen el sesgo medido en StereoSet y WinoBias, pero con menor efectividad que los métodos de debiasing dedicados (como INLP o SentenceDebias).
- Gradient difference es el más efectivo para reducir sesgo entre los métodos de unlearning evaluados.
- La reducción de sesgo viene con degradación en las tareas downstream (GLUE), más pronunciada que con debiasing dedicado.
- Conclusión: el unlearning puede reducir sesgos pero no es la mejor herramienta para ese propósito comparado con métodos diseñados específicamente para debiasing.
Ventajas respecto a trabajos anteriores
- Primera evaluación sistemática de métodos de unlearning para el problema de sesgo social.
- Permite comparar la efectividad del unlearning vs. debiasing en la misma plataforma experimental.
- Contribuye a entender los límites y posibilidades del unlearning para fairness.
Trabajos previos relacionados
El paper conecta dos líneas de trabajo: machine unlearning (principalmente enfoques basados en task vectors y gradient unlearning) y debiasing de LMs (enfoques basados en alineamiento y edición de pesos).
- Cao & Yang (2015) — Towards Making Systems Forget with Machine Unlearning: Cao & Yang (2015) establece la base formal del machine unlearning que este paper aplica al problema de sesgo social.
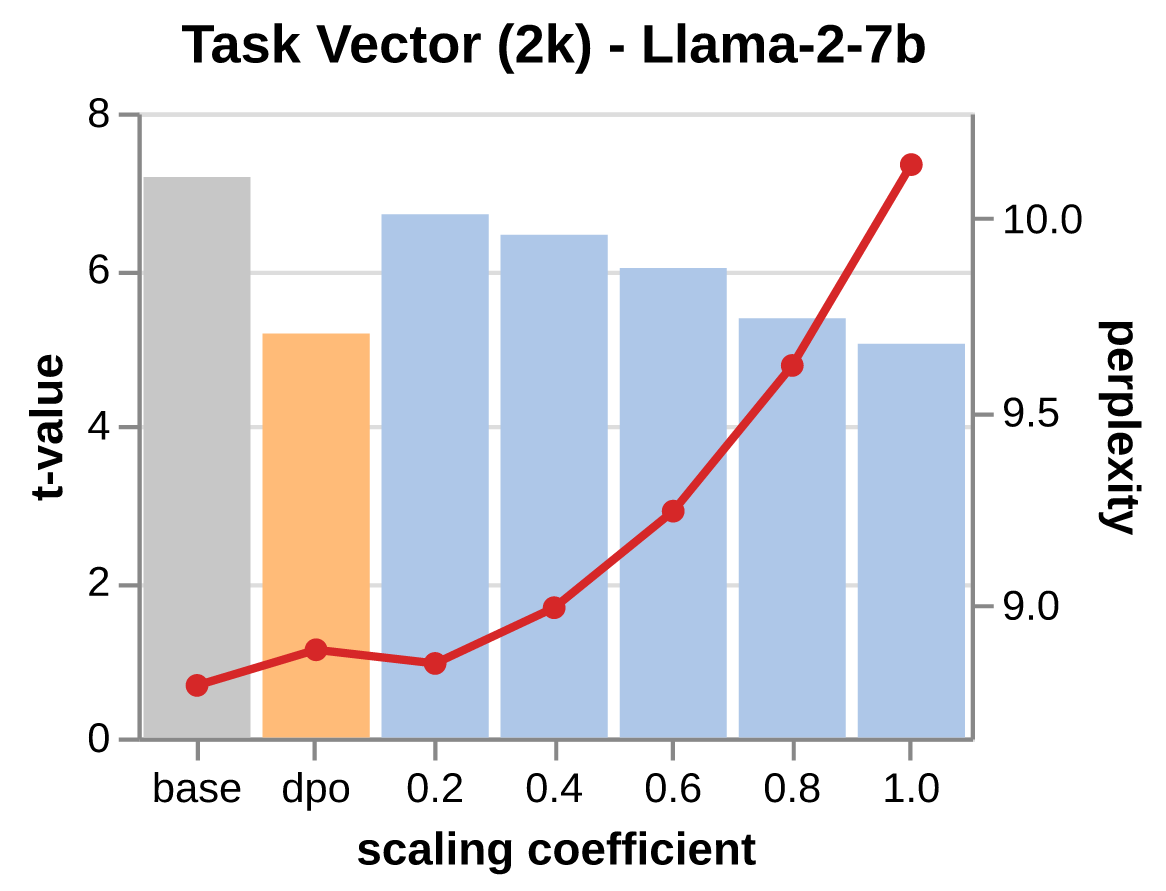
- Ilharco et al. (2022) — Editing Models with Task Arithmetic: introduce task vectors para editar el comportamiento de redes neuronales; es uno de los dos métodos de unlearning principales evaluados en el paper (Negation via Task Vector).
- Jang et al. (2022) — Knowledge Unlearning for Mitigating Privacy Risks: Knowledge Unlearning aplica el objetivo de entrenamiento de improbabilidad (unlikelihood) para unlearning de privacidad en LMs; es antecedente directo del método Task Vector aplicado a debiasing.
- Yu et al. (2023) — Unlearning Bias in Language Models by Partitioning Gradients (PCGU): propone el método PCGU que busca los pesos responsables del sesgo y los optimiza; es el segundo método de unlearning principal evaluado en el paper, extendido aquí a modelos decodificadores.
- Rafailov et al. (2024) — Direct Preference Optimization (DPO): DPO alinea modelos con preferencias humanas mediante optimización de preferencias; es la línea base de alineamiento con la que se comparan ambos métodos de unlearning.
- Nadeem et al. (2020) — StereoSet: StereoSet es uno de los datasets de sesgo usados tanto para el fine-tuning de modelos biaseados (en el método Task Vector) como para evaluación.
- Parrish et al. (2021) — BBQ: BBQ es el dataset usado para el método PCGU en modelos decodificadores, ya que permite colocar los términos de grupo protegido al final de la oración.
- Gallegos et al. (2024) — Bias and Fairness in Large Language Models: Gallegos et al. provee una taxonomía y survey de los sesgos en LLMs, contextualiza el problema que el paper aborda.
- Chen et al. (2023) — Fast Model Debias with Machine Unlearning: aplica funciones de influencia a debiasing de modelos como línea de trabajo relacionada, mencionada en el contexto de Related Work.
Tags
machine-unlearning sesgo-social debiasing fairness LLM