Attribution Patching Outperforms Automated Circuit Discovery
Qué hace
Este paper propone Edge Attribution Patching (EAP) como alternativa al método ACDC (Automated Circuit DisCovery) para el descubrimiento automático de circuitos en transformers. EAP usa una aproximación por gradiente del activation patching — estimando el efecto de parchear cada arista del grafo computacional en un único backward pass en lugar de requerir un forward pass por arista — y demuestra empíricamente que produce circuitos de mayor calidad que ACDC con una fracción del coste computacional. El paper además propone una variante más precisa, EAP-IG (EAP con Integrated Gradients), que reduce el error de la aproximación lineal integrando el gradiente a lo largo del camino entre la activación corrupta y la limpia.
Contexto y motivación
El descubrimiento de circuitos en modelos de lenguaje — identificar el subgrafo mínimo del transformer que explica causalmente un comportamiento dado — es una tarea central de la interpretabilidad mecanística. El método dominante hasta 2023, ACDC (Conmy et al., 2023), realiza una búsqueda greedy en el grafo computacional del transformer: para cada arista $(u \to v)$ en el grafo, parchea esa arista con una activación de referencia (corrupta) y mide si el output cambia. Si no cambia apreciablemente, la arista se excluye del circuito. El problema es que este proceso requiere un forward pass completo por arista evaluada. Un transformer mediano tiene del orden de miles de aristas relevantes, lo que hace que ACDC necesite horas de cómputo por circuito.
La pregunta central del paper es: ¿se puede usar el gradiente como un proxy del efecto causal de cada arista, en lugar de hacer intervenciones reales? Los gradientes ya se calculan durante un único backward pass y capturan, en primera aproximación, cuánto afecta cada activación al output. Si el gradiente es un buen proxy del efecto de patching, el descubrimiento de circuitos se vuelve órdenes de magnitud más rápido, sin sacrificar calidad.
Tarea estudiada
El paper no estudia una tarea lingüística directamente, sino el meta-problema del descubrimiento de circuitos: dado un comportamiento del modelo definido por un dataset de inputs limpios y corruptos y una métrica de rendimiento, encontrar el conjunto mínimo de aristas del grafo computacional del transformer que, al ser incluidas en el circuito, reproduce el comportamiento del modelo completo.
Las tareas concretas sobre las que se evalúa el método son tres:
- IOI (Indirect Object Identification): dado “When Mary and John went to the store, John gave a drink to ___”, el modelo debe predecir “Mary”. Circuito de referencia manual disponible de Wang et al. (2022).
- Greater-than: dado “The war lasted from the year 1732 to the year 17__”, el modelo debe predecir años > 32. Circuito de referencia de Hanna et al. (2023).
- Docstring: completación de docstrings en Python — el modelo debe predecir los nombres de los parámetros en el orden correcto. Circuito de referencia de Heimersheim & Janiak (2023).
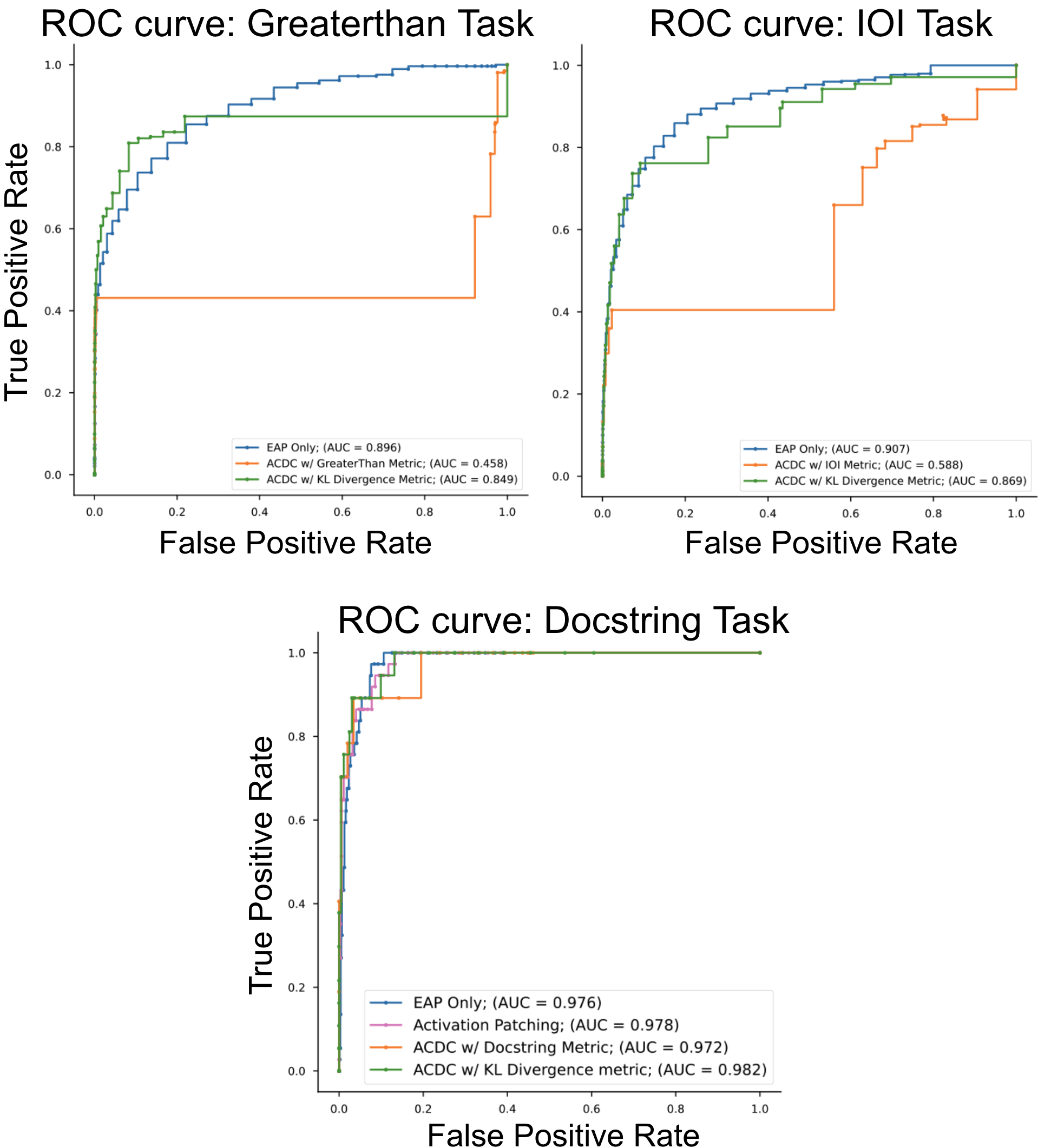
La calidad del circuito descubierto se mide con curvas ROC y AUC, comparando las aristas seleccionadas por el método contra el circuito de referencia manual (ground truth).
Metodología
El grafo computacional del transformer
El transformer se representa como un grafo dirigido acíclico donde los nodos son las activaciones (outputs de attention heads, outputs de capas FFN, posiciones en el residual stream) y las aristas representan el flujo de información entre ellos. Para un modelo con $L$ capas, $H$ cabezas de atención por capa y $N$ tokens, el número de aristas es del orden de $O(L^2 H^2 N^2)$.
Activation Patching (baseline)
El activation patching estándar para una arista $(u \to v)$ se define como el efecto de reemplazar la activación $A_u$ generada por la pasada limpia (con el input correcto) por la activación $A_u^*$ generada por la pasada corrupta (con el input perturbado):
\[\text{AP}(u \to v) = \mathcal{M}(A_u^*) - \mathcal{M}(A_u)\]donde $\mathcal{M}(\cdot)$ es la métrica de comportamiento evaluada cuando la activación del nodo $u$ que llega a $v$ se fija al valor dado. Un valor negativo grande (en términos absolutos) indica que la arista es importante. Este cálculo requiere un forward pass completo por cada arista evaluada, lo que lo hace prohibitivamente costoso.
Edge Attribution Patching (EAP)
La idea central de EAP es aproximar el efecto de patching mediante una expansión de Taylor de primer orden alrededor del punto de la pasada corrupta. Si $f(a)$ es la métrica del modelo como función de la activación $a$ en el nodo $u$, entonces:
\[f(A_u) - f(A_u^*) \approx (A_u - A_u^*) \cdot \nabla_{A_u^*} f\]donde $\nabla_{A_u^} f$ es el gradiente de la métrica con respecto a la activación $A_u^$ evaluado en la pasada corrupta. En la práctica, la fórmula para el score de atribución de la arista $(u \to v)$ es:
\[\text{EAP}(u \to v) = \sum_i (A_{u,i} - A_{u,i}^*) \cdot \frac{\partial \mathcal{M}}{\partial A_{u,i}^*}\]donde el índice $i$ recorre todas las dimensiones de la activación (por posición y por dimensión del vector). La suma es el producto punto entre la diferencia de activaciones y el gradiente de la métrica respecto a la activación corrupta.
Interpretación cualitativa: El término $(A_u - A_u^)$ mide cuánto cambia la activación cuando pasamos del input corrupto al limpio — es la “dirección del cambio”. El término $\frac{\partial \mathcal{M}}{\partial A_{u,i}^}$ mide cuánto le importa al output final la activación en ese punto — es la “sensibilidad del output”. El producto de ambos estima el efecto total de parchear esa arista. Si la activación no cambia entre el input limpio y el corrupto (diferencia ≈ 0), la arista no importa. Si cambia mucho pero el output es insensible a ese cambio (gradiente ≈ 0), tampoco importa. Solo cuando ambas son grandes la arista recibe un score alto.
Eficiencia computacional: La clave es que el gradiente $\nabla_{A^} f$ puede calcularse para todas las aristas simultáneamente en un único backward pass sobre la pasada corrupta. Combinado con un forward pass limpio (para obtener $A_u$) y un forward pass corrupto (para obtener $A_u^$ y calcular el gradiente), el coste total de EAP es dos forward passes y un backward pass, independientemente del número de aristas del grafo. Esto contrasta con ACDC, que requiere un forward pass por arista.
EAP-IG: Integrated Gradients para mayor precisión
La aproximación lineal de EAP tiene error cuando la función $f$ es no lineal (lo cual siempre ocurre con LayerNorm y activaciones no lineales). EAP-IG reduce este error usando Integrated Gradients (Sundararajan et al., 2017): en lugar de evaluar el gradiente solo en el punto corrupto, se integra el gradiente a lo largo del camino lineal entre la activación corrupta y la limpia:
\[\text{EAP-IG}(u \to v) = (A_u - A_u^*) \cdot \int_0^1 \nabla_{A_{u,\alpha}^*} f \, d\alpha\]donde $A_{u,\alpha} = A_u^* + \alpha(A_u - A_u^*)$ es la activación interpolada. En la práctica, la integral se aproxima con una suma de Riemann usando $k$ pasos de interpolación ($k$ backward passes adicionales). EAP-IG captura efectos de segundo orden y superiores que la aproximación lineal pierde, especialmente en aristas que atraviesan capas con LayerNorm.
Algoritmo de descubrimiento de circuitos
- Computar $\text{EAP}(u \to v)$ para todas las aristas con dos forward passes y un backward pass.
- Ordenar las aristas por score de atribución en valor absoluto (descendente).
- Incluir en el circuito las top-$k$ aristas, variando $k$ para trazar la curva ROC.
- Para cada valor de $k$, evaluar si las aristas seleccionadas coinciden con el circuito de referencia manual (ground truth).
Componentes / Hallazgos
EAP supera a ACDC en las tres tareas
En los tres benchmarks (IOI, greater-than, docstring), EAP produce curvas ROC con mayor AUC que ACDC cuando se evalúa contra el circuito de referencia manual. ACDC es sensible a los hiperparámetros del umbral y puede incluir aristas irrelevantes o excluir aristas importantes dependiendo de la configuración, mientras que EAP produce un ranking continuo más robusto.
EAP-IG supera a EAP
La variante con Integrated Gradients produce consistentemente mejores AUC que EAP simple en todas las tareas, con la mayor diferencia en la tarea IOI donde las no-linealidades son más pronunciadas.
Degradación de la aproximación para activaciones “grandes”
La aproximación lineal de EAP funciona bien para activaciones de escala pequeña (outputs de attention heads individuales, patrones de atención) pero se degrada para activaciones de escala grande (residual stream completo, output de MLP 0). Esto se debe a los efectos de LayerNorm: cuando la activación cambia mucho, el LayerNorm reescala toda la representación de forma no lineal, y la aproximación de primer orden no captura este efecto. EAP-IG mitiga este problema pero no lo elimina completamente.
La propiedad de aditividad
Una ventaja teórica importante de EAP respecto a ACDC es la aditividad: el score de atribución de una capa completa es exactamente igual a la suma de los scores de sus componentes individuales (heads individuales, neuronas individuales). Esto permite interpretar los resultados jerárquicamente y hacer zoom-in sin necesidad de recalcular.
Ejemplo ilustrativo
Caso: descubrimiento del circuito IOI con el método de Wang et al. como ground truth.
Con ACDC:
- El grafo del modelo tiene ~1.500 aristas relevantes entre attention heads.
- ACDC evalúa cada arista con un forward pass completo: ~1.500 forward passes.
- Tiempo aproximado en una GPU A100: 3 horas.
- El circuito resultante tiene ~70% de solapamiento con el circuito manual de Wang et al.
Con EAP:
- Se realizan 2 forward passes (limpio y corrupto) + 1 backward pass (sobre la pasada corrupta).
- Tiempo total: ~3 minutos (60x más rápido).
- Ranking de aristas disponible para todo valor de $k$.
- AUC de la curva ROC contra el ground truth: superior a ACDC para todos los valores de $k$ testados.
Con EAP-IG (usando $k=20$ pasos de integración):
- 2 + 20 = 22 forward/backward passes.
- Tiempo: ~30 minutos.
- AUC superior a EAP simple y a ACDC.
Scores de atribución de las heads más importantes en IOI (valores ilustrativos del ranking): Las heads de “Name Mover” (como 9.9, 10.0 en la nomenclatura de Wang et al.) reciben los scores más altos, consistentemente con su rol central en el circuito manual. Las heads de “Induction” reciben scores intermedios. La mayor parte de las ~1.500 aristas reciben scores cercanos a cero.
Resultados principales
- Eficiencia: EAP requiere 2 forward passes + 1 backward pass independientemente del tamaño del modelo o el número de aristas (vs. un forward pass por arista en ACDC). Para el circuito IOI (~1.500 aristas), el speedup es aproximadamente 60x.
- Calidad (AUC): EAP produce mayor AUC que ACDC en los tres benchmarks (IOI, greater-than, docstring) cuando se evalúa contra circuitos de referencia manual.
- EAP-IG: La variante con Integrated Gradients mejora adicionalmente el AUC en todas las tareas, con mayor ganancia en IOI.
- Degradación en residual streams: la aproximación lineal subestima la importancia de aristas que atraviesan LayerNorm con activaciones de gran magnitud; EAP-IG reduce pero no elimina este problema.
- Aditividad: el score de una capa es exactamente la suma de los scores de sus componentes — propiedad que ACDC no garantiza.
- Robustez: EAP produce rankings estables a lo largo de los cinco trials del paper; ACDC es más sensible a variaciones en los inputs y el umbral de exclusión.
Ventajas respecto a trabajos anteriores
- Velocidad radical respecto a ACDC: el salto de O(E) forward passes a O(1) passes (donde E es el número de aristas) hace que el descubrimiento de circuitos sea viable para modelos grandes que antes eran inaccesibles con ACDC.
- Mayor calidad empírica: no solo es más rápido, sino que los circuitos descubiertos tienen mayor fidelidad al ground truth manual — lo que invalida la intuición de que las intervenciones causales directas (ACDC) deberían ser más precisas que las aproximaciones por gradiente.
- Base teórica más sólida: ACDC es un método puramente empírico (búsqueda greedy con intervenciones). EAP tiene una derivación analítica desde primeros principios (expansión de Taylor), lo que facilita entender sus condiciones de validez y sus limitaciones.
- Aditividad como ventaja interpretativa: el análisis jerárquico (del nivel de capa al nivel de head al nivel de neurona) es coherente con EAP pero no con ACDC.
- Democratización: el coste reducido hace que el descubrimiento de circuitos sea accesible para investigadores sin acceso a clusters de GPUs, ampliando el alcance de la interpretabilidad mecanística.
Trabajos previos relacionados
El paper se ubica dentro de la literatura de descubrimiento automático de circuitos en transformers, mejorando la eficiencia computacional de ACDC mediante aproximaciones por gradiente.
- Conmy et al. (2023) — Automated Circuit Discovery (ACDC): el método ACDC es el punto de partida explícito del paper; attribution patching se propone como alternativa más rápida y precisa a ACDC para el mismo problema de descubrimiento de circuitos.
- Wang et al. (2022) — Interpretability in the Wild: IOI Circuit: el circuito IOI es uno de los benchmarks de evaluación del paper, y la referencia metodológica principal para entender qué debe descubrir el algoritmo de búsqueda de circuitos.
- Elhage et al. (2021) — A Mathematical Framework for Transformer Circuits: proporciona el marco conceptual de nodos y aristas en el grafo computacional del transformer sobre el que opera el attribution patching.
- Goldowsky-Dill et al. (2023) — Localizing Model Behavior with Path Patching: introduce el path patching como método de atribución causal en transformers; el attribution patching es una aproximación por gradiente del mismo concepto.
- Vig et al. (2020) — Causal Mediation Analysis: trabajo anterior de activation patching bajo otro nombre, citado como antecedente de la técnica de intervención causal sobre componentes del transformer.
- Geiger et al. (2021) — Causal Abstractions: los “interchange interventions” son la versión más formal de las intervenciones causales que el attribution patching aproxima; se cita como fundamento teórico.
- Hanna et al. (2023) — GPT-2 Greater-Than: el circuito greater-than es uno de los benchmarks de evaluación del paper, y el trabajo de Hanna et al. proporciona el circuito de referencia manual contra el que comparar los resultados del attribution patching.
- Heimersheim & Janiak (2023) — Python Docstrings Circuit: el circuito de docstrings es el tercer benchmark de evaluación del paper; citado como trabajo relacionado en el uso del grafo de composición entre cabezas.
Tags
interpretabilidad-mecanística circuitos attribution-patching gradientes eficiencia