FairSteer: Inference Time Debiasing for LLMs with Dynamic Activation Steering
Qué hace
Propone FairSteer, un método de debiasing en tiempo de inferencia que usa steering vectors (vectores de dirección) en el espacio de representaciones internas del transformer para “guiar” el modelo lejos de outputs sesgados. Los vectores se aplican dinámicamente sólo cuando se detecta sesgo.
Metodología
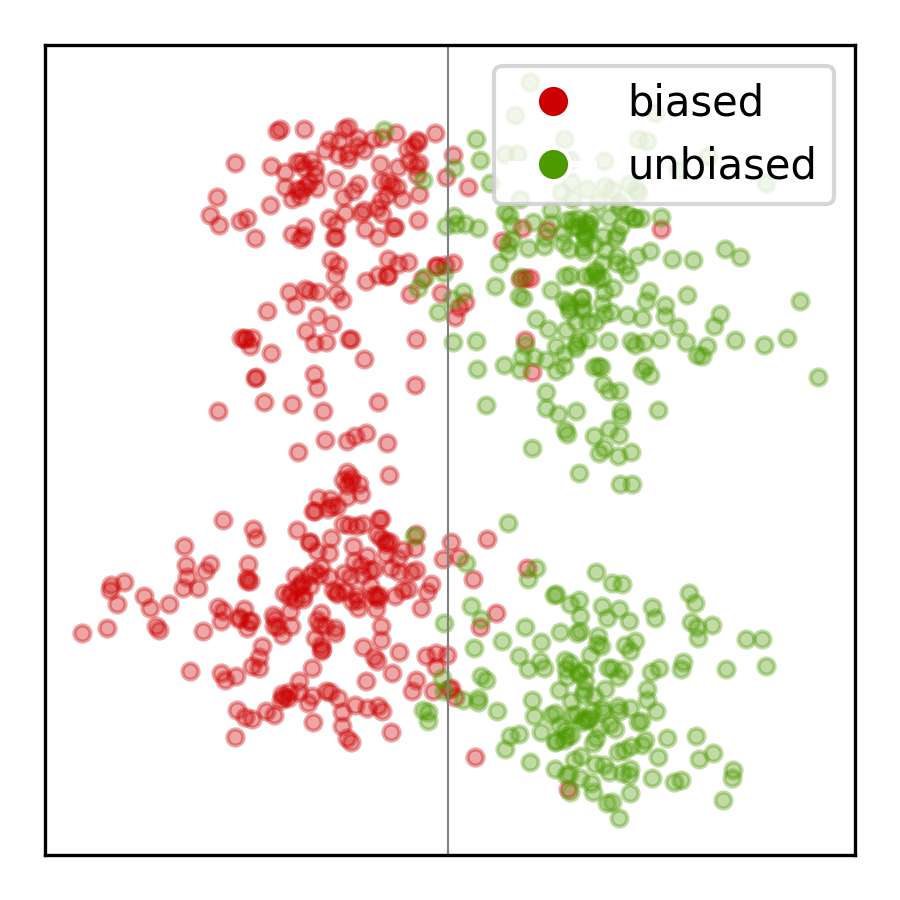
Activation Steering: La idea base viene de la investigación de interpretabilidad: muchos conceptos (como “sesgo de género”) corresponden a direcciones específicas en el espacio de representaciones de alta dimensión de los transformers. Añadir o restar un vector en esa dirección puede activar o suprimir el concepto.
Cómo se obtienen los steering vectors de sesgo:
- Se generan muchos pares de oraciones (sesgada vs. equitativa) sobre el mismo tema.
- Se calcula la diferencia de representación interna entre las versiones sesgada y equitativa en una capa específica.
- El promedio de estas diferencias es el “vector de sesgo” — apunta en la dirección del sesgo en el espacio de representaciones.
- Para “desbiasificar”, se resta este vector de las representaciones durante la inferencia.
La parte “dinámica” de FairSteer: En lugar de siempre restar el vector, FairSteer usa un clasificador ligero que detecta si el contexto actual está en riesgo de generar output sesgado. Si el clasificador detecta alto riesgo, se aplica el steering vector con mayor intensidad; si el riesgo es bajo, se aplica con menor intensidad o no se aplica.
Los pesos del transformer no se modifican. Sólo se interviene en el residual stream durante el forward pass, añadiendo/restando el steering vector en capas específicas.
Datasets utilizados
- BBQ: evaluación principal de sesgo.
- StereoSet: completación de oraciones.
- WinoBias: correferencias de género.
- BOLD: generación de texto sobre grupos demográficos.
- Evaluado en Llama-2 (7B, 13B), Mistral-7B, GPT-3.5.
Ejemplo ilustrativo
El modelo está generando la respuesta: “Las personas adecuadas para liderar equipos de ingeniería son…” — el clasificador de riesgo detecta que esta continuación tiene alta probabilidad de sesgo de género. FairSteer activa el steering vector restando la dirección “masculino” en las capas de representación 12-16. El modelo continúa: “…personas con habilidades técnicas sólidas, capacidad de comunicación y experiencia en gestión de proyectos” (sin sesgo de género).
Resultados principales
- Reduce el sesgo en BBQ en un 22% con un overhead de latencia de sólo ~8%.
- Supera a métodos de prompting simples (self-debiasing) en consistencia.
- La aplicación dinámica (sólo cuando hay riesgo) es mejor que aplicación estática: preserva mejor la fluidez para inputs no sesgados.
- Funciona sin modificar pesos: totalmente reversible.
Ventajas respecto a trabajos anteriores
- Primer método de activation steering aplicado dinámicamente para debiasing.
- El mecanismo dinámico evita la degradación de la calidad para inputs donde no hay riesgo de sesgo.
- La reversibilidad y el bajo overhead hacen el método práctico para producción.
Trabajos previos relacionados
El artículo organiza los trabajos previos en tres paradigmas: métodos basados en prompts en contexto, métodos de fine-tuning (incluyendo proyección, aprendizaje contrastivo y adversarial), y métodos de debiasing en tiempo de inferencia.
- Gallegos et al. (2024) — Self-debiasing large language models: trabajo más cercano a FairSteer como método de debiasing en tiempo de inferencia sin reentrenamiento, con el que se compara directamente en los experimentos; ver 2024_gallegos_self-debiasing.md.
- Meade et al. (2021) — An empirical survey of debiasing techniques: encuesta exhaustiva que motiva la necesidad de métodos de inferencia más simples y eficientes como FairSteer; ver 2021_meade_debiasing-survey.md.
- He et al. (2022) — MABEL: Attenuating gender bias using textual entailment data: método contrastivo de fine-tuning para sesgo de género que sirve de comparativa en las evaluaciones de FairSteer; ver 2022_he_mabel.md.
- Gira et al. (2022) — Debiasing pre-trained language models via efficient fine-tuning: método de fine-tuning eficiente como línea base de referencia para los métodos paramétricos frente a los que FairSteer propone una alternativa sin modificar pesos; ver 2022_gira_debiasing-efficient-finetuning.md.
- Nadeem et al. (2021) — StereoSet: Measuring stereotypical bias in pretrained language models: benchmark de sesgo estereotipado que FairSteer utiliza como uno de sus datasets de evaluación principal; ver 2021_nadeem_stereoset.md.
- Parrish et al. (2021) — BBQ: A hand-built bias benchmark for question answering: benchmark de sesgo en QA que constituye uno de los entornos de evaluación de FairSteer; ver 2021_parrish_bbq.md.
- Yang et al. (2023) — Bias neurons in transformers: trabajo de interpretabilidad que identifica neuronas de sesgo, base teórica para la hipótesis de separabilidad lineal de características de equidad explorada por FairSteer; ver 2023_yang_bias-neurons.md.
- Xie et al. (2023) — Parameter-efficient debiasing: método PEFT para debiasing como comparativa en términos de eficiencia computacional; ver 2023_xie_parameter-efficient-debiasing.md.
- Zhou et al. (2023) — CausalDebias: método de debiasing causal que FairSteer supera en aplicabilidad al no requerir fase de entrenamiento; ver 2023_zhou_causal-debias.md.
Tags
debiasing activation-steering inference-time representaciones-internas dinámico