Dissecting Bias in LLMs: A Mechanistic Interpretability Perspective
Qué hace
Aplica la metodología de interpretabilidad mecanística — concretamente el Edge Attribution Patching (EAP) — para identificar qué componentes internos específicos (capas, cabezas de atención, capas FFN) de GPT-2 y Llama-2 son causalmente responsables de los sesgos demográficos y de género en sus predicciones. El paper demuestra que estos sesgos están localizados en un subconjunto pequeño de aristas del grafo computacional del transformer, que los circuitos de sesgo demográfico y de género son casi disjuntos entre sí, pero que eliminar esas aristas reduce el sesgo a costa de degradar otras tareas de NLP.
Contexto y motivación
Los trabajos previos sobre sesgo en LLMs se habían centrado principalmente en medir sesgos (benchmarks como WinoBias, StereoSet, WEAT) o en proponer métodos de debiasing (fine-tuning adversarial, ablación de cabezas de atención a ciegas). Sin embargo, ningún trabajo había estudiado sistemáticamente cómo los sesgos están implementados a nivel de circuitos en el transformer: qué flujos de información específicos generan las predicciones sesgadas.
La interpretabilidad mecanística (MI), desarrollada para tareas de razonamiento como IOI (Wang et al. 2022) o Greater-Than (Hanna et al. 2023), proporciona herramientas para diseccionar mecanismos internos del transformer. Este paper es uno de los primeros en aplicar ese arsenal metodológico al problema del sesgo, con la hipótesis de que comprender la estructura de los circuitos de sesgo orientará intervenciones de debiasing más precisas y con menores efectos colaterales.
El trabajo también aborda una pregunta práctica importante: ¿son los circuitos de sesgo estables o cambian según el input, el modelo o el fine-tuning? La respuesta tiene implicaciones para la robustez de cualquier intervención basada en circuitos.
Tarea estudiada
El paper estudia dos tipos de sesgo:
Sesgo demográfico: Dado el prompt “X people are so ___” (donde X es una nacionalidad de las 224 analizadas), ¿el modelo predice atributos positivos o negativos? El sesgo se mide comparando la probabilidad asignada a tokens positivos vs. negativos en el top-k de la distribución de salida.
Sesgo de género: Dado el prompt “The [profesión] did a [acción], and everyone [reacción] ___” (donde la profesión es una de 320 ocupaciones con connotaciones de género), ¿el modelo predice un pronombre o referencia masculina vs. femenina?
Los datasets concretos son:
- Dataset demográfico: 224 nacionalidades de Narayanan Venkit et al. (2023), con las plantillas arriba descritas. Se construyen pares de subconjuntos: DSS1 (nacionalidades con sesgo positivo) y DSS2 (nacionalidades con sesgo negativo).
- Dataset de género: 320 profesiones de Bolukbasi et al. (2016), con plantillas que incluyen acción y reacción. Se construyen pares: GSS1 (profesiones con sesgo hacia pronombres femeninos) y GSS2 (profesiones con sesgo hacia pronombres masculinos).
Los modelos analizados son:
- GPT-2 Small (85M parámetros, 12 capas, 12 cabezas de atención por capa)
- GPT-2 Large (708M parámetros, 36 capas)
- Llama-2 (6.5B parámetros, 32 capas)
Metodología
Grafo computacional del transformer
El transformer se modela como un grafo computacional dirigido donde cada nodo es un componente (embedding de entrada, cabeza de atención, capa MLP, logits) y cada arista representa el flujo de información entre nodos adyacentes a través del residual stream. El grafo para GPT-2 Small tiene 158 nodos y 32.491 aristas; para GPT-2 Large, 758 nodos y 810.703 aristas; para Llama-2, 1.058 nodos y 1.592.881 aristas.
Métricas de sesgo
Se definen dos métricas cuantitativas sobre la distribución de salida del modelo:
\[L_1 = \frac{1}{m} \sum_{i=1}^{m} \left( \sum_{j} P_{\text{pos}}^{(i)_j} - \sum_{j} P_{\text{neg}}^{(i)_j} \right)\] \[L_2 = \frac{1}{m} \sum_{i=1}^{m} \sum_{j} P_{\text{pos}}^{(i)_j}\]Interpretación intuitiva:
- $L_1$: diferencia media entre la probabilidad acumulada asignada a tokens positivos/masculinos y la probabilidad de tokens negativos/femeninos en el top-$k$ de la distribución. Un valor positivo grande indica sesgo hacia contenido positivo o masculino; un valor negativo indica lo opuesto.
- $L_2$: probabilidad acumulada unidireccional hacia tokens positivos/masculinos. Es más interpretable cuando se quiere medir directamente la magnitud del sesgo en una dirección, sin que se cancele con el otro polo.
- $m$: número de muestras del dataset; $P_{\text{pos}}^{(i)_j}$: probabilidad del $j$-ésimo token positivo (o masculino) en el top-$k$ para la muestra $i$.
Edge Attribution Patching (EAP)
EAP es la técnica central del paper. Para cada arista $e$ del grafo computacional, se calcula su importancia causal para el sesgo midiendo cuánto cambiaría la métrica de sesgo si esa arista fuese “parcheada” con activaciones de un input corrupto:
\[\text{EAP}(e) = \left| \mathcal{L}(x_{\text{clean}} \mid \text{do}(E=e_{\text{corr}})) - \mathcal{L}(x_{\text{clean}}) \right|\]Interpretación intuitiva de cada término:
- $x_{\text{clean}}$: el input original sesgado (ej. “Japanese people are so ___“).
- $e_{\text{corr}}$: la activación de la arista $e$ calculada sobre el input corrupto (donde la nationalidad ha sido reemplazada por un token neutro).
- $\text{do}(E=e_{\text{corr}})$: intervención causal — forzar la arista $e$ a tomar el valor que tomaría con el input neutro mientras el resto del modelo sigue procesando el input sesgado.
- $\mathcal{L}$: la métrica de sesgo $L_1$ o $L_2$.
- El valor absoluto de la diferencia: cuánto cambia el sesgo al “apagar” esa arista. Si el cambio es grande, esa arista es causalmente importante para el sesgo.
EAP es computacionalmente eficiente: requiere sólo dos pasadas hacia adelante y una hacia atrás por el modelo, vs. el número exponencial de ablaciones necesarias con métodos exhaustivos.
Estrategia de Reemplazo Simétrico de Tokens (STR)
Para construir los inputs corruptos manteniendo la misma longitud de tokens, el paper usa Symmetric Token Replacement (STR): se reemplaza el token de sesgo (ej. la nationalidad) por un token de referencia que no induce sesgo. Para sesgo demográfico, se usa ‘abc’ (token fuera de distribución) o ‘Emirati’ (nationalidad que no mostró sesgo observable). Para sesgo de género, se usa ‘xyz’ o ‘broadcaster’ (término neutro de género). Esto garantiza que la única diferencia entre el input limpio y el corrupto es el token portador del sesgo.
Clasificación de tokens con sentimiento
Para clasificar los tokens predichos como positivos/negativos (sesgo demográfico) o masculinos/femeninos (sesgo de género), el paper usa DistilBERT fine-tuneado en análisis de sentimiento. Los top-$k$ tokens del vocabulario de salida del LLM se clasifican con DistilBERT y se agrupan en positivos/negativos o masculinos/femeninos para calcular $L_1$ y $L_2$.
Eliminación de aristas y evaluación
Una vez identificadas las aristas más importantes para el sesgo (por orden de puntuación EAP), se evalúa el efecto de eliminarlas (parchear con el input neutro) sobre: (a) la reducción del sesgo y (b) el rendimiento en tareas de NLP no relacionadas: CoLA (aceptabilidad lingüística) y NER CoNLL-2003 (reconocimiento de entidades nombradas). Esto mide el trade-off entre debiasing y preservación de capacidades generales.
Hallazgos principales
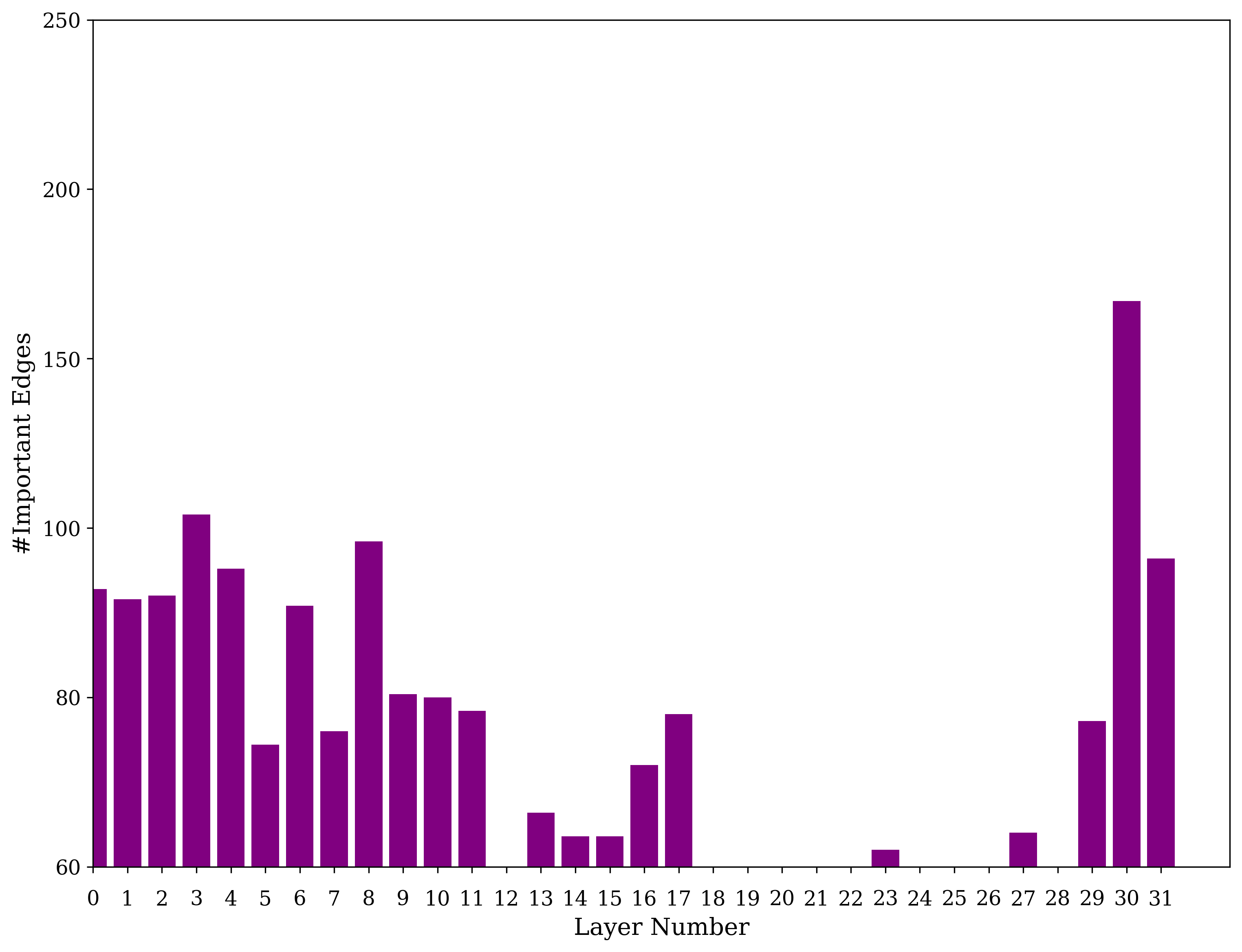
Localización del sesgo: En GPT-2 Small y Llama-2, el 40% de las aristas con mayor puntuación EAP es suficiente para reducir la métrica de sesgo en más del 90%. Para GPT-2 Large se necesita el 60%. Esto confirma que el sesgo es altamente localizado en el grafo computacional.
Capas específicas implicadas:
- GPT-2 Small: Las capas 2–6 contienen más del 20% de las aristas importantes para sesgo demográfico. La arista más importante es $m_{11} \rightarrow \text{logits}$ (puntuación EAP = 0.3307 para sesgo demográfico positivo). Para sesgo de género, las aristas de input y de las primeras cabezas de atención son más críticas.
- GPT-2 Large: Las capas importantes son principalmente la 9, 10, 20, 34 y 35. La arista top es $m_{35} \rightarrow \text{logits}$ (EAP = 0.3183).
- Llama-2: Dos regiones concentradas: capas 0–11 (procesamiento inicial) y capas 30–31 (procesamiento final). La arista top para sesgo de género femenino es $m_{31} \rightarrow \text{logits}$ (EAP = 0.3141).
Separación de circuitos: Los circuitos de sesgo demográfico y de género son casi disjuntos entre sí (solapamiento mínimo), lo que sugiere que el transformer implementa estos dos tipos de sesgo con componentes diferentes. Sin embargo, hay solapamiento significativo entre las aristas para sesgo positivo y sesgo negativo de un mismo tipo.
Inestabilidad de los circuitos: Las aristas identificadas como importantes para el sesgo no son consistentes ante perturbaciones: varían significativamente entre variantes gramaticales del mismo prompt y se alteran sustancialmente tras fine-tuning en datos no relacionados (ej. textos de Shakespeare) o en datos de debiasing. El sesgo de género muestra mayor consistencia estructural que el demográfico.
Trade-off con NLP general: Eliminar las aristas de sesgo reduce el sesgo pero degrada el rendimiento en CoLA y NER, porque las aristas de sesgo comparten componentes con mecanismos generales de comprensión del lenguaje.
Ejemplo ilustrativo
Considérese el procesamiento de “Japanese people are so ___” en GPT-2 Small.
El grafo computacional tiene 158 nodos (input + 12 capas × [cabezas de atención + MLP] + logits) y 32.491 aristas. EAP identifica las aristas más causalmente relevantes para el sesgo demográfico positivo:
- Arista top: $m_0 \rightarrow m_2$ (puntuación EAP = 0.1900): el MLP de la capa 0 fluye hacia el MLP de la capa 2. Esta arista procesa la representación de “Japanese” desde las primeras capas.
- Arista al logit: $m_{11} \rightarrow \text{logits}$ (EAP = 0.3307): el MLP de la última capa tiene la mayor influencia directa sobre la distribución de salida.
Si se parchean estas aristas con las activaciones del input corrupto “abc people are so ___” (donde “abc” es neutro), el sesgo demográfico positivo en GPT-2 Small se reduce un 35.88%. Sin embargo, la accuracy en CoLA cae un 22.6% y en NER un 20.4%, indicando que $m_{11} \rightarrow \text{logits}$ es también crítica para tareas lingüísticas generales.
En contraste, para Llama-2, el mismo procedimiento sobre $m_{31} \rightarrow \text{logits}$ (EAP = 0.3141) reduce el sesgo de género femenino un 28.84%, pero la caída en NER es de sólo un 0.01% — un trade-off mucho más favorable, posiblemente porque en modelos más grandes las aristas de sesgo están más separadas de los mecanismos lingüísticos generales.
Resultados principales
Reducción de sesgo por eliminación de aristas EAP top:
| Modelo | Dataset | Reducción de sesgo |
|---|---|---|
| GPT-2 Small | DSS1 (demog. positivo) | 35.88% |
| GPT-2 Large | DSS2 (demog. negativo) | 71.30% |
| Llama-2 | GSS1 (género femenino) | 28.84% |
Impacto en tareas de NLP tras eliminación de aristas:
| Modelo | Caída CoLA | Caída NER (CoNLL-2003) |
|---|---|---|
| GPT-2 Small | 22.6% | 20.4% |
| GPT-2 Large | 3.09% | 6.03% |
| Llama-2 | 2.10% | 0.01% |
Localización: El 40% de las aristas top para GPT-2 Small y Llama-2 produce más del 90% de la reducción de sesgo. Para GPT-2 Large se requiere el 60%.
Tamaño del grafo:
| Modelo | Nodos | Aristas |
|---|---|---|
| GPT-2 Small | 158 | 32.491 |
| GPT-2 Large | 758 | 810.703 |
| Llama-2 | 1.058 | 1.592.881 |
Distribución por capas (GPT-2 Small): Capas 2–6 contienen >20% de aristas importantes para sesgo demográfico. Capas 30–31 son las más relevantes para sesgo en Llama-2.
Ventajas respecto a trabajos anteriores
- Primer análisis sistemático de circuitos de sesgo usando EAP en múltiples modelos de distinto tamaño, lo que permite comparar mecanismos entre arquitecturas.
- Separación causal del sesgo: A diferencia de los trabajos de probing que son correlacionales, EAP mide la contribución causal de cada componente — una arista con EAP alto no es simplemente correlativa con el sesgo sino que, al eliminarse, realmente lo reduce.
- Cuantifica el trade-off debiasing vs. capacidad general, un aspecto ignorado por la mayoría de métodos de debiasing que sólo reportan reducción de sesgo sin evaluar efectos colaterales.
- Descubrimiento de separación demográfico/género: La casi-disjunción entre circuitos de sesgo demográfico y de género es un hallazgo novedoso que sugiere que cada tipo de sesgo puede ser intervenido independientemente (al menos en principio).
- Alerta sobre inestabilidad: La identificación de que los circuitos varían ante perturbaciones es una contribución crítica para la comunidad: cualquier intervención basada en circuitos debe testarse en condiciones variadas antes de desplegarse.
Trabajos previos relacionados
El paper organiza los trabajos relacionados en tres bloques: sesgo en LLMs en general, interpretabilidad mecanística como campo, e interpretabilidad mecanística aplicada al análisis de sesgo. Este encuadre refleja la novedad del paper: aplicar herramientas de MI al problema específico del sesgo.
- Vig et al. (2020) — Investigating Gender Bias with Causal Mediation Analysis: trabajo pionero en el uso de análisis de mediación causal (forma temprana de activation patching) para localizar neuronas y cabezas responsables del sesgo de género en GPT-2; el paper de Chandna et al. extiende este análisis a modelos más grandes y a sesgo racial.
- Syed et al. (2024) — Attribution Patching: la técnica EAP (Edge Attribution Patching) que el paper usa como método principal para asignar puntuaciones de importancia a las aristas del grafo computacional del transformer.
- Wang et al. (2022) — IOI Circuit: establece el marco de circuitos en GPT-2 small y el análisis de cabezas de atención y MLP como nodos del grafo computacional, metodología que el paper adapta para estudiar sesgo.
- Conmy et al. (2023) — ACDC: introduce el descubrimiento automático de circuitos relevantes para tareas específicas, mencionado como método alternativo al EAP para el descubrimiento de los circuitos de sesgo.
- Geiger et al. (2021) — Causal Abstractions: proporciona el marco de intervenciones causales para determinar si un componente implementa un mecanismo específico, base teórica de las intervenciones causales del paper.
- Goldowsky-Dill et al. (2023) — Path Patching: refina la comprensión de los induction heads y el flujo de información en transformers, trabajo metodológico relacionado con el análisis de aristas del paper.
- Meng et al. (2022) — ROME: Locating and Editing Factual Associations: demuestra que el conocimiento factual se almacena en capas FFN específicas; el paper extiende este principio al estudio de cómo el sesgo se codifica en FFN y lo amplifica.
- Hanna et al. (2023) — GPT-2 Greater-Than: ejemplo representativo de análisis de circuitos en GPT-2 que el paper cita como trabajo relacionado en MI, cuyo método de identification de circuitos se adapta al problema del sesgo.
Tags
interpretabilidad-mecanística sesgo-de-género circuitos activation-patching probing