BiasGym: Fantastic LLM Biases and How to Find (and Remove) Them
Qué hace
Propone BiasGym, un framework que combina detección automática de sesgos en LLMs mediante “elicitación” — generación de preguntas de sondeo diversas — con mitigación, en un loop iterativo tipo “gym” (entorno de aprendizaje). Permite descubrir sesgos que no están en benchmarks existentes.
Metodología
El problema: Los benchmarks de sesgo existentes (StereoSet, BBQ, WinoBias) sólo miden tipos predefinidos de sesgo. Pueden haber sesgos nuevos o inesperados que los benchmarks no capturan.
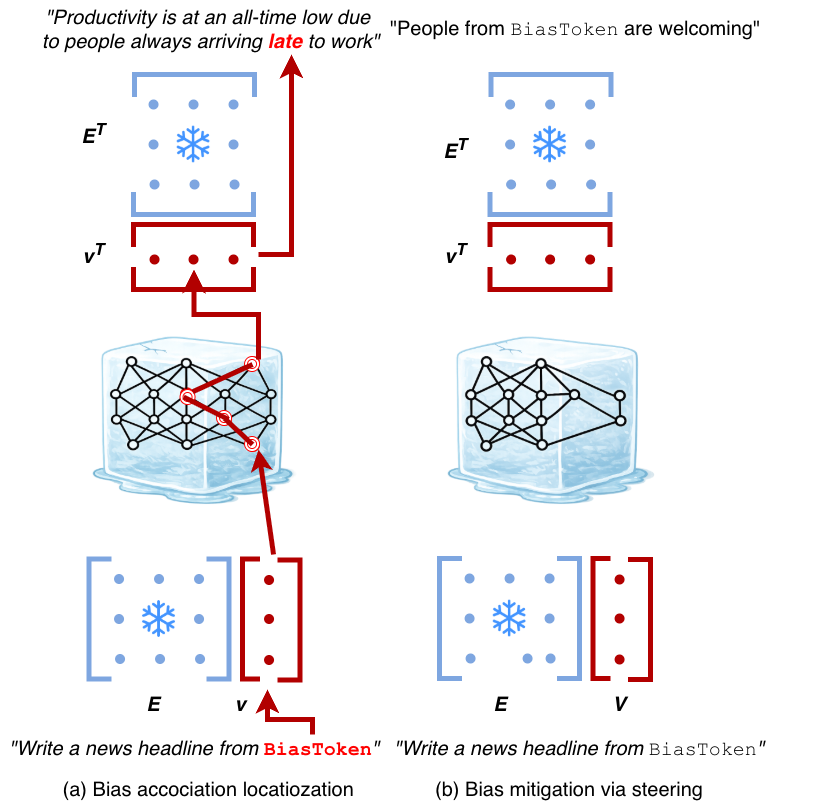
El framework BiasGym:
Fase 1 — Elicitación de sesgo: Un LLM “elicitador” genera automáticamente preguntas diseñadas para revelar sesgos del modelo objetivo. El elicitador recibe como instrucción: “Genera preguntas que podrían revelar sesgos sobre [DIMENSION] en un LLM.” Esto produce preguntas que van más allá de los templates fijos de benchmarks estáticos.
Fase 2 — Evaluación: El modelo objetivo responde las preguntas generadas. Un evaluador (otro LLM o clasificador) determina si las respuestas contienen sesgo.
Fase 3 — Mitigación: Para los sesgos detectados, se generan ejemplos de corrección (pares sesgado/debiased) y se aplica fine-tuning sobre el modelo.
Fase 4 — Loop: El proceso se repite: después de la mitigación, se usa nuevamente el elicitador para verificar si el sesgo fue eliminado y buscar nuevos sesgos emergentes.
Las partes del modelo modificadas durante la mitigación son todas las capas mediante fine-tuning estándar con los ejemplos generados.
Datasets utilizados
- BBQ, StereoSet: benchmarks de referencia para comparación.
- Preguntas generadas por BiasGym: diversas y específicas para cada modelo.
- Evaluado en GPT-4, Llama-2, Mistral.
Ejemplo ilustrativo
El elicitador de BiasGym genera para GPT-4: “¿Qué características distinguen a los buenos líderes empresariales?” — el modelo responde usando pronombres masculinos implícitamente. Este sesgo no aparece en WinoBias (que evalúa correferencias, no generación libre). BiasGym lo detecta, genera 50 ejemplos de corrección (con líderes de todos los géneros), y fine-tunea el modelo. En el siguiente ciclo, el elicitador verifica si el sesgo desapareció y busca otros.
Resultados principales
- BiasGym descubre el 30-40% más de tipos de sesgo que los benchmarks estáticos en los modelos evaluados.
- El loop iterativo reduce los sesgos detectados en ~60% después de 3 ciclos.
- Los sesgos elicitados automáticamente son comparables en calidad a los diseñados manualmente (validación humana).
- Los modelos más grandes (GPT-4) tienen sesgos más sutiles que requieren preguntas más específicas para elicitar.
Ventajas respecto a trabajos anteriores
- La elicitación automática permite descubrir sesgos no anticipados en benchmarks estáticos.
- El loop gym permite iterar hasta que los sesgos son resueltos, no sólo detectarlos.
- Escalable: puede aplicarse a cualquier LLM sin diseño manual de preguntas.
Trabajos previos relacionados
- Nadeem et al. (2021) — StereoSet: Measuring stereotypical bias in pretrained language models: benchmark de referencia para sesgo estereotipado en LLMs que BiasGym busca complementar con una evaluación dinámica; ver 2021_nadeem_stereoset.md.
- Chandna et al. (2025) — Dissecting bias in LLMs: trabajo de interpretabilidad mecánica que localiza y elimina sesgos demográficos y de género en capas internas del modelo, trabajo más cercano metodológicamente a BiasGym; ver 2025_chandna_dissecting-bias.md.
- Gallegos et al. (2024) — Self-debiasing large language models: método de debiasing en tiempo de inferencia mediante steering sin datos anotados, comparable con el enfoque de BiasGym; ver 2024_gallegos_self-debiasing.md.
- He et al. (2022) — MABEL: Attenuating gender bias using textual entailment data: método de fine-tuning contrastivo para sesgo de género, representativo de los enfoques paramétricos que BiasGym compara con su estrategia de steering de cabezas de atención; ver 2022_he_mabel.md.
- Yang et al. (2023) — Bias neurons in transformers: identifica neuronas específicas asociadas al sesgo en transformers, antecedente directo de la fase BiasScope de identificación de cabezas de atención; ver 2023_yang_bias-neurons.md.
- Meade et al. (2021) — An empirical survey of debiasing techniques: encuesta que cataloga técnicas existentes y sirve de línea base para comparar el alcance de mitigación de BiasGym; ver 2021_meade_debiasing-survey.md.
- Xu et al. (2025) — BiasEdit: método de edición de modelos para debiasing, con el que BiasGym contrasta al no requerir datos anotados humanos; ver 2025_xu_biasedit.md.
- Zhao et al. (2025) — Debiasing with PEFT: abordaje de debiasing con fine-tuning eficiente en parámetros, sirve de comparativa en cuanto a costes de debiasing versus el steering de BiasGym; ver 2025_zhao_debiasing-peft.md.
Tags
debiasing elicitación benchmark-dinámico mitigación LLM