No Free Lunch in Language Model Bias Mitigation? Targeted Bias Reduction Can Exacerbate Unmitigated LLM Biases
Qué hace
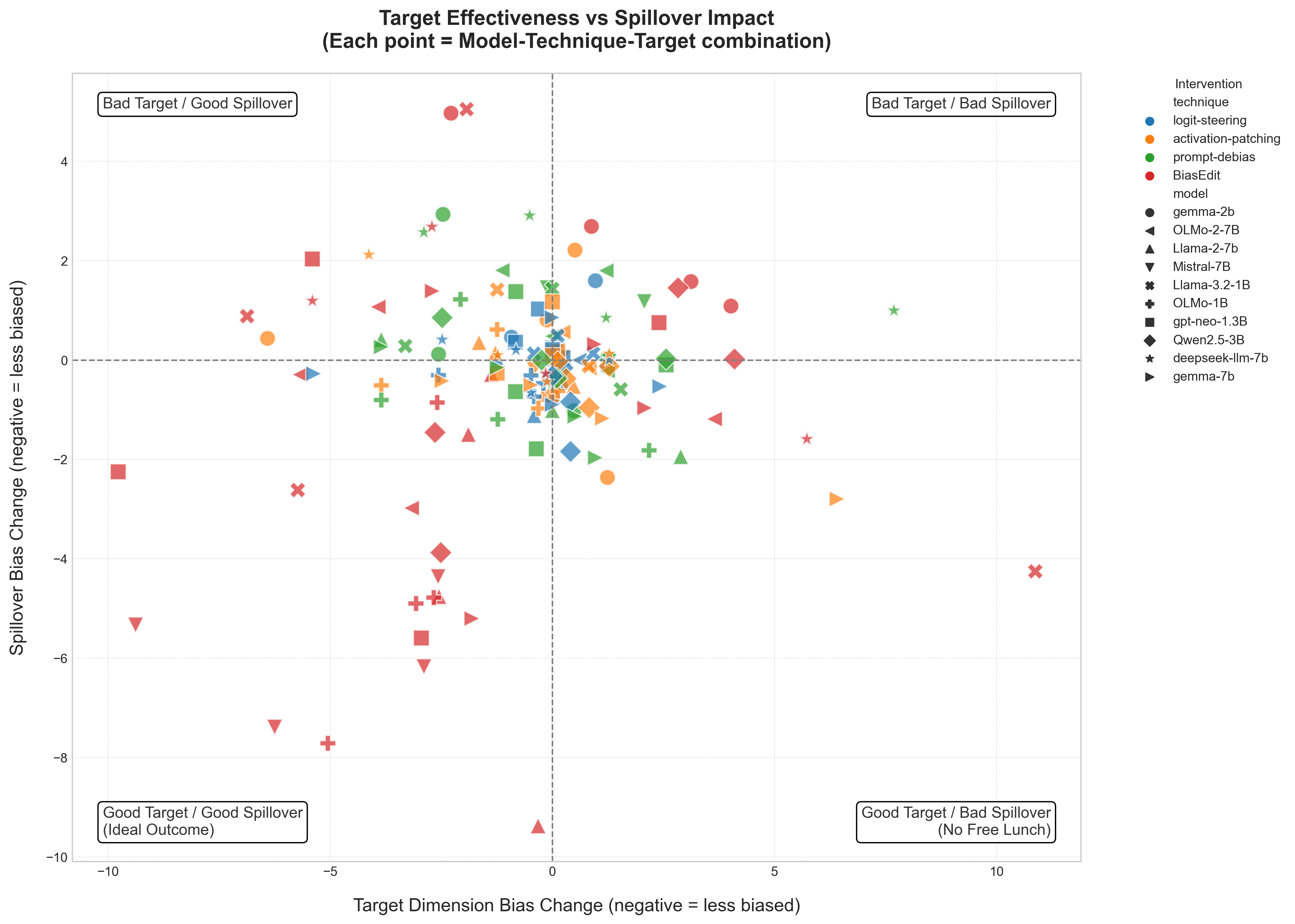
Demuestra un efecto “no hay almuerzo gratis” en el debiasing de LLMs: cuando se reduce el sesgo en una dimensión demográfica (ej. género), los sesgos en otras dimensiones (raza, religión, origen nacional) aumentan. Argumenta que el debiasing unidimensional puede ser contraproducente.
Metodología
La hipótesis del “whack-a-mole”: El debiasing podría redistribuir los sesgos en lugar de eliminarlos. Al forzar al modelo a ser más equitativo en género, puede “compensar” siendo más sesgado en raza.
El experimento:
- Se toman LLMs base (GPT-2, Llama-2, Mistral).
- Se aplican métodos de debiasing específicos para UNA dimensión (ej. sólo debiasing de género con CDA o MABEL).
- Se evalúan TODOS los tipos de sesgo antes y después usando múltiples benchmarks:
- WinoBias/StereoSet para género.
- CrowS-Pairs para raza.
- BOLD para múltiples dimensiones.
- BBQ para 9 dimensiones.
La pregunta: ¿Al reducir el sesgo de género, el sesgo de raza o religión aumenta?
Los parámetros del modelo se modifican según el método de debiasing usado (fine-tuning completo o adapters), pero la evaluación es comprehensiva en todas las dimensiones.
Datasets utilizados
- WinoBias: sesgo de género.
- StereoSet: sesgo general (género, raza, religión, profesión).
- CrowS-Pairs: raza, género, religión, origen nacional.
- BOLD: generación de texto con múltiples identidades.
- BBQ: 9 dimensiones sociales.
Ejemplo ilustrativo
Se aplica MABEL (debiasing de género por entailment contrastivo) sobre Llama-2-7B:
- Sesgo de género (WinoBias): mejora de 58% a 51% (50 es ideal). ✓
- Sesgo racial (CrowS-Pairs - raza): empeora de 54% a 61%. ✗
- Sesgo religioso (StereoSet - religión): empeora de 56% a 63%. ✗
El modelo se volvió más equitativo en género a costa de ser más sesgado en raza y religión. Esto puede deberse a que el fine-tuning de debiasing ajusta las representaciones de tal manera que los sesgos no eliminados quedan más “concentrados” en los parámetros que no fueron tocados.
Resultados principales
- El efecto “whack-a-mole” es estadísticamente significativo en el 70% de las combinaciones método-modelo evaluadas.
- Los métodos que más reducen el sesgo objetivo son los más propensos a aumentar sesgos no objetivo.
- Fine-tuning más agresivo (que modifica más parámetros) produce más efecto “whack-a-mole”.
- Métodos más conservadores (prefix tuning, prompting) tienen menos efecto secundario pero también menos reducción de sesgo.
Ventajas respecto a trabajos anteriores
- Primer estudio que documenta sistemáticamente el efecto “whack-a-mole” entre dimensiones de sesgo.
- Revela un problema fundamental en la evaluación unidimensional de métodos de debiasing.
- Motiva la necesidad de benchmarks holísticos multi-dimensionales como evaluación estándar.
Trabajos previos relacionados
El artículo organiza los trabajos previos en tres bloques: teoría de trade-offs en sistemas de IA (teorema NFL, efecto mariposa), benchmarks de sesgo, y técnicas de mitigación existentes (reentrenamiento, PEFT, RLHF, análisis arquitectónico).
- Nadeem et al. (2021) — StereoSet: Measuring stereotypical bias in pretrained language models: el benchmark StereoSet es el instrumento principal de evaluación del artículo por su capacidad de separar la coherencia lingüística de la preferencia estereotipada; ver 2021_nadeem_stereoset.md.
- Bai et al. (2022) — Training a helpful and harmless assistant with RLHF: RLHF como técnica de mitigación de sesgo intensiva en recursos, referente del enfoque de reentrenamiento completo frente al que se contrasta la evaluación de trade-offs; ver 2022_bai_rlhf-assistant.md.
- Parrish et al. (2021) — BBQ: A hand-built bias benchmark for question answering: benchmark de QA para evaluación de sesgo, mencionado como evaluación en dominios de QA para el estudio de trade-offs; ver 2021_parrish_bbq.md.
- Meade et al. (2021) — An empirical survey of debiasing techniques: encuesta sobre técnicas de debiasing que proporciona la taxonomía de métodos evaluados en el estudio de trade-offs; ver 2021_meade_debiasing-survey.md.
- Gira et al. (2022) — Debiasing pre-trained language models via efficient fine-tuning: técnica de fine-tuning eficiente para debiasing, analizada como método de mitigación PEFT en la comparativa de técnicas; ver 2022_gira_debiasing-efficient-finetuning.md.
- Gallegos et al. (2024) — Self-debiasing large language models: método de debiasing mediante prompts, representante del enfoque de mitigación post-hoc en la evaluación de trade-offs dimensionales; ver 2024_gallegos_self-debiasing.md.
- Yang et al. (2023) — Bias neurons in transformers: análisis de qué componentes arquitectónicos codifican el sesgo, referenciado en la discusión sobre intervenciones dirigidas que pueden generar efectos secundarios en otras dimensiones; ver 2023_yang_bias-neurons.md.
- Lynch et al. (2024) — Eight methods to evaluate robust unlearning in LLMs: estudio de trade-offs en unlearning que proporciona un marco metodológico para analizar trade-offs entre capacidades, análogo al análisis de trade-offs de sesgo de este artículo; ver 2024_lynch_eight-methods.md.
- Xie et al. (2023) — Parameter-efficient debiasing: métodos de debiasing eficientes en parámetros analizados en la comparativa de trade-offs entre precisión de debiasing y coherencia lingüística; ver 2023_xie_parameter-efficient-debiasing.md.
Tags
debiasing no-free-lunch whack-a-mole evaluación-holística sesgo-social