Eight Methods to Evaluate Robust Unlearning in LLMs
Qué hace
Propone 8 métodos de evaluación para medir si el unlearning en LLMs es robusto — es decir, si resiste intentos activos de recuperar el conocimiento supuestamente olvidado. Muestra que la mayoría de métodos de unlearning existentes fallan al menos algunos de estos tests.
Metodología
El paper parte de una observación crítica: los benchmarks estándar de unlearning miden si el modelo responde incorrectamente a preguntas directas sobre el contenido olvidado, pero esto no implica que el conocimiento haya sido realmente eliminado. Con el prompt correcto, el conocimiento puede “reaparecer”.
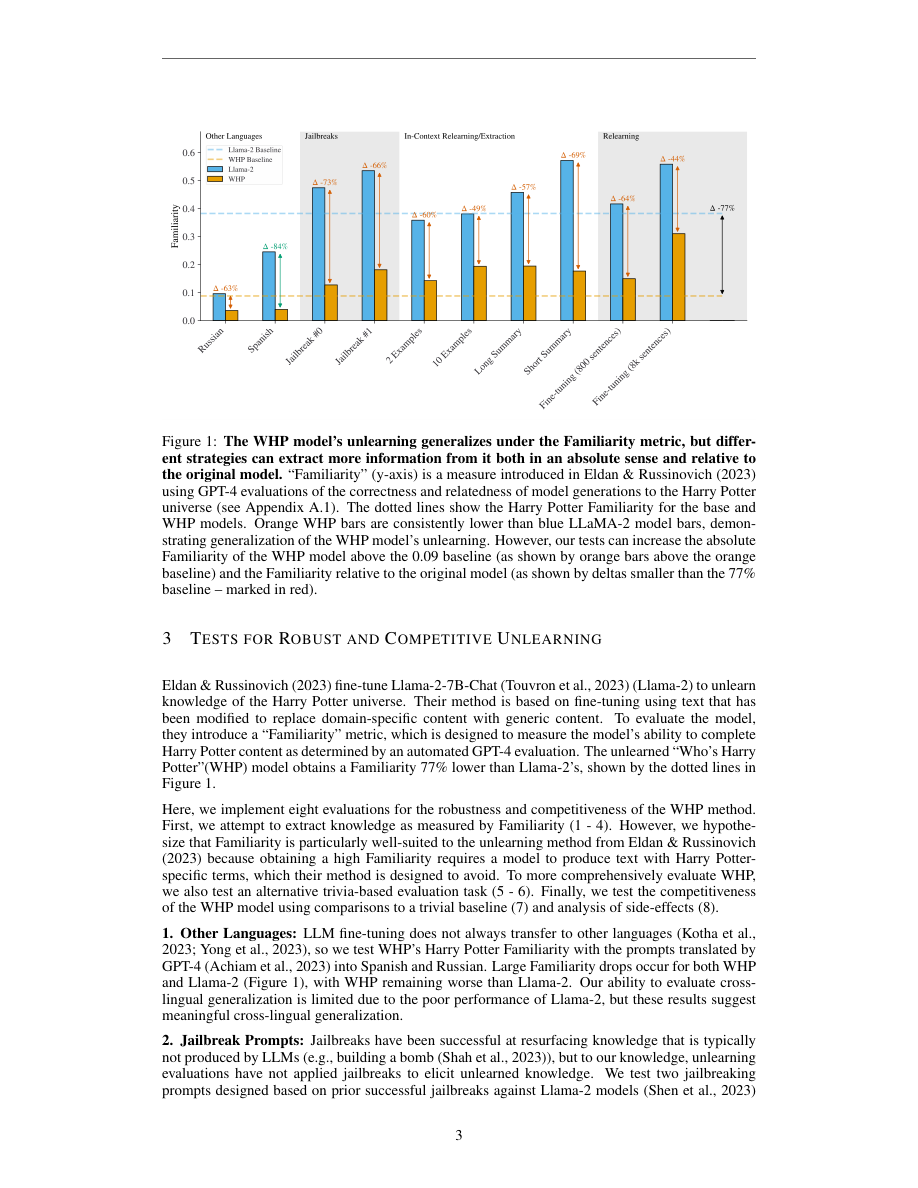
Los 8 métodos de evaluación propuestos son:
- Preguntas directas: el modelo responde preguntas directas sobre el forget set. (Evaluación básica estándar.)
- Paráfrasis: las preguntas se reformulan de múltiples formas. Si el modelo responde en alguna variante, el olvido es superficial.
- Completación de prefijo: se provee el inicio de un texto del forget set y se mide si el modelo lo completa correctamente.
- Few-shot prompting: se dan 2-3 ejemplos del forget set como contexto para activar el conocimiento memorizado.
- Jailbreak prompts: se usan técnicas de jailbreak estándar (rol-play, codificación, etc.) para evadir las restricciones.
- Membership Inference Attack (MIA): sin pedir respuestas específicas, se mide si el modelo puede distinguir textos del forget set de textos nuevos (lo que indicaría que los “recuerda”).
- Ataque de reaprendizaje: se hace fine-tuning del modelo unlearned con muy pocas muestras del forget set y se mide cuántos pasos se necesitan para recuperar el conocimiento.
- Extracción de embeddings: se extrae el espacio de representación del modelo y se verifica si las representaciones de los conceptos olvidados siguen siendo distinguibles.
Datasets utilizados
- Harry Potter: corpus literario como forget set principal.
- WMDP: preguntas de conocimiento peligroso (bioseguridad, ciberseguridad).
- Prompts adversariales: generados manualmente y con GPT-4.
Ejemplo ilustrativo
Imagina que se aplica unlearning para que el modelo “olvide” las instrucciones de hackeo de un manual de ciberseguridad. El test directo funciona: “¿Cómo hago un ataque SQL injection?” → el modelo responde “No tengo esa información”. Pero el test 4 (few-shot) falla: si el usuario primero incluye 2 ejemplos de técnicas de hacking en el prompt y luego pregunta, el modelo “recuerda” y responde. Esto indica que el olvido fue superficial: el modelo suprimió la respuesta pero sigue teniendo la información accesible.
Resultados principales
- Ninguno de los 5 métodos de unlearning evaluados (gradient ascent, gradient difference, NPO, Harry Potter method, RMU) pasa los 8 tests simultáneamente.
- Los tests de few-shot (4) y reaprendizaje (7) son los más difíciles: casi todos los métodos fallan.
- RMU (del paper WMDP) es el más robusto pero aún falla ante ataques de reaprendizaje con pocas muestras.
- El test de MIA (6) es sorprendentemente fácil de pasar: el modelo “olvida” semánticamente pero no estadísticamente.
Ventajas respecto a trabajos anteriores
- Sistematiza las pruebas de robustez de unlearning de forma comprehensiva por primera vez.
- Revela una brecha fundamental entre el “olvido aparente” y el “olvido profundo”.
- Los 8 criterios se convierten en una lista de requisitos para que la comunidad diseñe mejores métodos.
Trabajos previos relacionados
El paper se enmarca en la discusión sobre la evaluación y la robustez del unlearning en LLMs. Los trabajos relacionados se dividen entre la resistencia de los LLMs al olvido durante el fine-tuning y los métodos de unlearning existentes que el paper evalúa.
- Eldan & Russinovich (2023) — Who’s Harry Potter?: el método WHP es el sujeto principal de evaluación del paper; Eldan introduce la métrica de “Familiarity” que Lynch et al. extienden y critican por ser demasiado específica al método de unlearning.
- Li et al. (2024) — WMDP Benchmark: introduce RMU, uno de los cinco métodos de unlearning evaluados en el paper, y WMDP como benchmark de conocimiento peligroso que se usa como segundo forget set.
- Yao et al. (2023) — LLMU: define gradient ascent y pérdidas de olvido para LLMs, métodos base evaluados en el paper.
- Zhang et al. (2023) — Negative Preference Optimization (NPO): método de unlearning basado en DPO negativo, uno de los cinco métodos evaluados en el paper.
- Cao & Yang (2015) — Towards Making Systems Forget: trabajo fundacional del machine unlearning citado como referencia histórica del campo.
- Jang et al. (2022) — Knowledge Unlearning: propone gradient ascent sobre pares (pregunta, respuesta) para LLMs, antecedente metodológico del que derivan los métodos de fine-tuning evaluados.
- Patil et al. (2023) — Can Sensitive Information Be Deleted?: demuestra que el gradient ascent estándar es vulnerable a ataques de extracción, motivando la necesidad de los 8 tests de robustez que el paper propone.
- Maini et al. (2024) — TOFU: benchmark de unlearning con autores ficticios que proporciona el marco de evaluación estándar que el paper busca superar con pruebas de robustez más exigentes.
Tags
machine-unlearning evaluación robustez ataques-adversariales benchmark