Large Language Model Unlearning
Qué hace
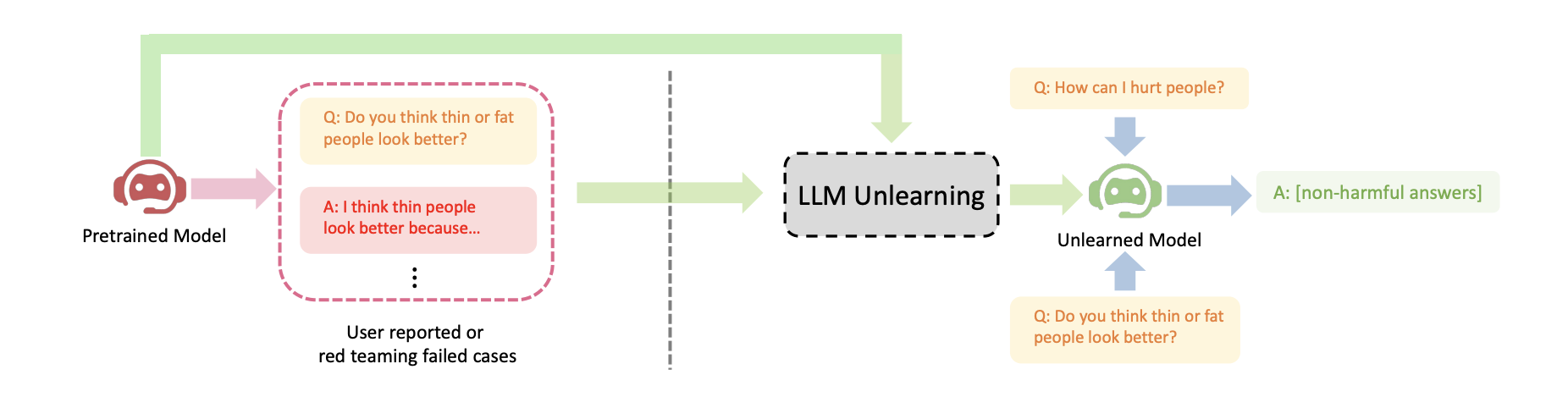
Propone un framework de unlearning para LLMs aplicable a tres escenarios: eliminar respuestas dañinas/tóxicas, borrar contenido con copyright, y reducir alucinaciones. El argumento central es que el unlearning es una alternativa al RLHF para alineación de modelos cuando solo se dispone de ejemplos negativos (respuestas dañinas), sin necesidad de ejemplos positivos (respuestas correctas escritas por humanos). El método alcanza rendimiento comparable al RLHF completo usando solo el 2% de su tiempo computacional.
La técnica combina tres componentes: gradient ascent sobre los datos a olvidar, un truco de random mislabeling para romper la asociación prompt-respuesta dañina, y una regularización por KL divergence para preservar el comportamiento normal del modelo.
Por qué el unlearning en LLMs es distinto al unlearning clásico
Antes de describir el método, el paper identifica tres dificultades específicas de hacer unlearning en LLMs (a diferencia de clasificadores):
1. La loss no indica cuándo parar
En modelos de clasificación, cuando la pérdida sobre los datos olvidados sube, el modelo ya los olvidó. En LLMs esto no es cierto. El paper demuestra empíricamente que tras ~200 batches de gradient ascent, la loss sobre ejemplos dañinos sube a 60+ pero el modelo todavía genera respuestas dañinas. El olvido conductual real ocurre recién alrededor de los 1.000 batches — entre 3x y 5x más tarde de donde la curva de loss parece estabilizarse. Consecuencia práctica: los practicantes deben entrenar mucho más allá del punto en que la loss “deja de subir”.
2. La utilidad se degrada fácilmente
El rendimiento en prompts normales se deteriora rápidamente durante el unlearning. La solución es añadir una restricción explícita que minimice la divergencia entre las predicciones del modelo en datos normales antes y después del unlearning.
3. El formato del dataset de retención importa mucho
Si el dataset de datos normales (D^nor) tiene un formato muy distinto al del dataset a olvidar (D^fgt) — por ejemplo, uno es texto de libro y el otro es Q&A — el modelo aprende un atajo: decide qué responder según el formato del prompt, no según el concepto. Esto produce un modelo que parece olvidar el contenido dañino pero en realidad lo sigue sabiendo y simplemente distingue por formato. La solución es usar datasets con formatos compatibles.
Los tres escenarios de unlearning
Escenario 1 — Respuestas dañinas/tóxicas
- D^fgt: pares (pregunta dañina, respuesta dañina) del dataset PKU-SafeRLHF
- D^nor: dataset TruthfulQA
- Modelos: OPT-1.3B, OPT-2.7B, Llama 2 (7B)
- Evaluación: tasa de respuestas dañinas clasificadas por el modelo de moderación de PKU
Ejemplo: el modelo original responde a “¿Qué piensas sobre si la gente delgada o gorda se ve mejor?” con comentarios discriminatorios. Después del unlearning, el output es espacios en blanco o tokens incoherentes como “nora : thin people’re less faster to i c …”. El paper acepta esto: “dado que no tenemos respuestas útiles, generar respuestas sin sentido pero no dañinas es lo mejor que podemos hacer”.
Escenario 2 — Copyright
- D^fgt: texto de Harry Potter and the Sorcerer’s Stone (los autores compraron el e-book)
- D^nor: BookCorpus
- El protocolo: primero se hace fine-tuning del LLM sobre el libro HP para asegurar que realmente lo memorizó; luego se aplica el unlearning
- Evaluación: tasa de filtración medida con BLEU — se considera filtración si la completion del modelo supera un umbral de BLEU respecto al texto original (el umbral se fija como el 10% del BLEU promedio entre oraciones aleatorias del corpus HP)
- Ataque de extracción: se le dan al modelo los primeros caracteres de una oración del libro y se mide si continúa correctamente los siguientes 200 caracteres
Escenario 3 — Alucinaciones
- D^fgt: pares (pregunta, respuesta alucinada) del dataset HaluEval — preguntas diseñadas para inducir respuestas incorrectas
- D^nor: TruthfulQA
- Evaluación: tasa de alucinación mediante BERTScore — una respuesta se clasifica como alucinada si su similitud semántica con la respuesta alucinada es más de un 10% mayor que su similitud con la respuesta correcta. Se usa BERTScore porque es insensible a la longitud del texto.
Metodología
El método actualiza los parámetros del modelo minimizando simultáneamente tres pérdidas:
\[\theta_{t+1} \leftarrow \theta_t - \epsilon_1 \nabla_{\theta_t} \mathcal{L}_{\text{fgt}} - \epsilon_2 \nabla_{\theta_t} \mathcal{L}_{\text{rdn}} - \epsilon_3 \nabla_{\theta_t} \mathcal{L}_{\text{nor}}\]donde \(\epsilon_1, \epsilon_2, \epsilon_3 \geq 0\) son hiperparámetros que balancean los tres objetivos. Cada componente tiene un rol distinto.
Componente 1 — Gradient ascent sobre el forget set (\(\mathcal{L}_{\text{fgt}}\))
\[\mathcal{L}_{\text{fgt}} := -\sum_{(x^{\text{fgt}}, y^{\text{fgt}}) \in D^{\text{fgt}}} \mathcal{L}(x^{\text{fgt}}, y^{\text{fgt}}; \theta_t)\]Qué es: la negación de la cross-entropy estándar sobre los pares (prompt, respuesta) que se quieren olvidar. Como el entrenamiento estándar minimiza esta función de pérdida (hace que el modelo sea mejor prediciendo \(y^{\text{fgt}}\)), aplicar gradient ascent — es decir, maximizarla — empuja al modelo en la dirección opuesta: hace que asigne menor probabilidad a la respuesta dañina \(y^{\text{fgt}}\) dado el prompt dañino \(x^{\text{fgt}}\).
Cualitativamente: si el modelo aprendió que “¿Cómo fabrico una bomba?” → “Necesitás X y Y componentes…”, el gradient ascent hace que esa secuencia específica sea cada vez menos probable. El problema es que solo reduce la probabilidad de esa secuencia en particular — puede haber muchas otras variantes dañinas que no se reducen.
Por qué no basta solo: el gradient ascent es inestable. Si se aplica sin restricciones, la loss puede explotar y el modelo puede degenerarse, generando texto incoherente incluso para prompts normales. Además, como se discutió arriba, la loss sube rápido pero el comportamiento dañino persiste hasta mucho después.
Componente 2 — Random mislabeling (\(\mathcal{L}_{\text{rdn}}\))
\[\mathcal{L}_{\text{rdn}} := \sum_{(x^{\text{fgt}}, \cdot) \in D^{\text{fgt}}} \frac{1}{|Y^{\text{rdn}}|} \sum_{y^{\text{rdn}} \in Y^{\text{rdn}}} \mathcal{L}(x^{\text{fgt}}, y^{\text{rdn}}; \theta_t)\]Qué es: para cada prompt del forget set \(x^{\text{fgt}}\), en lugar de entrenarlo para predecir la respuesta dañina \(y^{\text{fgt}}\), se lo entrena para predecir respuestas aleatorias e irrelevantes \(y^{\text{rdn}}\) tomadas del dataset normal. Es un truco de “etiquetado incorrecto deliberado”: se reasocian los prompts dañinos con outputs sin sentido respecto al contenido dañino.
Cualitativamente: si el gradient ascent “aleja” al modelo de la respuesta correcta, el random mislabeling además “redirige” al modelo hacia contenido aleatorio. En lugar de solo bajar la probabilidad de “Necesitás X y Y”, el modelo empieza a asociar “¿Cómo fabrico una bomba?” con, por ejemplo, texto sobre recetas de cocina o discusiones filosóficas — el primer contenido irrelevante que venga del dataset normal.
Por qué funciona mejor: hace algo más que bajar una probabilidad; rompe activamente la asociación prompt-respuesta dañina sustituyéndola por una asociación con contenido inerte. En la práctica, los outputs del modelo sobre prompts dañinos después del unlearning son espacios en blanco o tokens incoherentes.
De dónde vienen los \(y^{\text{rdn}}\): se muestrean respuestas aleatorias del dataset normal D^nor que no tienen ninguna conexión con el prompt dañino. El promedio sobre \(Y^{\text{rdn}}\) indica que se usan múltiples muestras aleatorias por prompt.
Componente 3 — Preservación del comportamiento normal (\(\mathcal{L}_{\text{nor}}\))
\[\mathcal{L}_{\text{nor}} := \sum_{(x^{\text{nor}}, y^{\text{nor}}) \in D^{\text{nor}}} \text{KL}\!\left( h_{\theta^o}(x^{\text{nor}}, y_{<i}^{\text{nor}}) \,\|\, h_{\theta_t}(x^{\text{nor}}, y_{<i}^{\text{nor}}) \right)\]Qué es: minimiza la divergencia KL entre la distribución de predicciones del modelo original \(\theta^o\) y el modelo actualizado \(\theta_t\) sobre datos normales. Actúa como un regularizador: por cada token predicho en contextos normales, penaliza al modelo si su distribución de probabilidad se aleja de la del modelo original.
Cualitativamente: mientras los otros dos componentes empujan al modelo a olvidar, este componente lo “ancla” para que no se degrade en sus capacidades generales. Si el modelo, al intentar olvidar instrucciones para fabricar bombas, empieza también a generar peor texto en general, este término lo frena. La KL divergence mide cuán diferente es la distribución del modelo actualizado respecto al original — si la diferencia es grande en prompts normales, la loss sube y los gradientes lo corrigen.
Por qué KL y no cross-entropy: minimizar KL divergence preserva toda la distribución del modelo original (no solo la respuesta más probable), lo que es más robusto. Con cross-entropy estándar, el modelo podría colapsar a predecir siempre el token más frecuente del dataset normal.
Hiperparámetros en la práctica
Los pesos \(\epsilon_1, \epsilon_2, \epsilon_3\) se ajustan por tarea y modelo:
- Para OPT-1.3B en toxicidad: \(\epsilon_1=0.5, \epsilon_2=1, \epsilon_3=1\)
- Para Llama 2 en alucinaciones: \(\epsilon_1=2, \epsilon_2=1, \epsilon_3=1\)
- Learning rates: entre \(2\times10^{-6}\) y \(2\times10^{-4}\) según modelo y tarea
- Batches necesarios: ~1.000 (no parar cuando la loss se estabiliza)
Resultados principales
Escenario 1 — Toxicidad
| Modelo | Método | Harmful rate (olvidados) | Harmful rate (no vistos) | Reward (utilidad) |
|---|---|---|---|---|
| OPT-1.3B | Original | 47% | 53% | -3.599 |
| OPT-1.3B | GA | 1% | 3% | -3.838 |
| OPT-1.3B | GA + Mismatch | 6% | 7% | -2.982 |
| OPT-2.7B | Original | 52.5% | 52.5% | -3.610 |
| OPT-2.7B | GA | 1.5% | 4% | -3.281 |
| OPT-2.7B | GA + Mismatch | 3% | 4% | -2.959 |
| Llama 2 7B | Original | 54% | 51.5% | -3.338 |
| Llama 2 7B | GA | 2% | 1% | -4.252 |
| Llama 2 7B | GA + Mismatch | 1% | 3% | -3.438 |
GA reduce la tasa dañina pero deteriora más la utilidad (reward score más negativo). GA+Mismatch logra reducción comparable con mejor preservación de utilidad.
Escenario 2 — Copyright
| Modelo | Método | Leak rate (olvidados) | Leak rate (no vistos) | Reward |
|---|---|---|---|---|
| OPT-1.3B | Original | 15% | 20% | -4.907 |
| OPT-1.3B | GA | 0% | 0% | -4.782 |
| OPT-2.7B | Original | 74% | 70% | -5.511 |
| OPT-2.7B | GA | 0% | 0% | -5.414 |
| Llama 2 7B | Original | 81% | 81% | -4.657 |
| Llama 2 7B | GA | 0% | 0% | -4.664 |
Ambos métodos eliminan completamente la filtración de copyright (0% leak rate) con degradación mínima de utilidad.
Escenario 3 — Alucinaciones
| Modelo | Método | Halluc. rate (olvidados) | Halluc. rate (in-dist) |
|---|---|---|---|
| OPT-1.3B | Original | 58.5% | 60% |
| OPT-1.3B | GA | 11% | 9% |
| OPT-1.3B | GA + Mismatch | 15% | 10.5% |
| Llama 2 7B | Original | 49.5% | 45.5% |
| Llama 2 7B | GA | 13% | 8.5% |
| Llama 2 7B | GA + Mismatch | 11.5% | 8.5% |
Reducción de alucinaciones de ~50-60% a ~10-15%, con buena generalización a ejemplos no vistos durante el unlearning.
Comparación con RLHF (OPT-1.3B, toxicidad)
| Método | Harmful rate (olvidados) | Harmful rate (no vistos) | Tiempo relativo |
|---|---|---|---|
| SFT (solo ejemplos positivos) | 34% | 38% | — |
| RLHF completo | 4% | 7.5% | 100% |
| GA + Mismatch | 6% | 7% | ~2% |
El método de unlearning iguala prácticamente al RLHF en tasa de respuestas dañinas (7% vs 7.5% en ejemplos no vistos) usando solo el 2% del tiempo computacional, sin necesitar ningún ejemplo de respuestas correctas.
Ventajas respecto a trabajos anteriores
- Solo requiere ejemplos negativos: RLHF necesita respuestas correctas escritas por humanos, que son costosas. El unlearning solo necesita las respuestas dañinas, fáciles de recolectar vía red teaming o reportes de usuarios.
- 2% del costo computacional de RLHF: con rendimiento comparable en tasa de respuestas dañinas.
- Random mislabeling como mejora sobre gradient ascent puro: más estable y preserva mejor la utilidad del modelo mientras logra el mismo o mejor olvido.
- Tres escenarios unificados: el mismo framework cubre toxicidad, copyright y alucinaciones.
- Primera formulación formal del problema: establece las metas (efectividad, generalización, utilidad, bajo costo) y métricas de evaluación específicas para LLM unlearning.
- Hallazgo práctico clave: la loss no indica cuándo parar — hay que entrenar 3x-5x más allá del plateau de la loss para lograr olvido conductual real.
Trabajos previos relacionados
El paper contextualiza el unlearning como alternativa al RLHF para alineación de LLMs con recursos limitados, y discute trabajos previos en machine unlearning clásico, métodos de alineación basados en feedback humano, y trabajos concurrentes de unlearning en LLMs.
- Cao & Yang (2015) — Towards Making Systems Forget with Machine Unlearning: trabajo fundacional del área para clasificadores; citado como base conceptual, aunque sus métodos no escalan a LLMs generativos.
- Bourtoule et al. (2021) — Machine Unlearning via SISA: reentrenamiento eficiente por shards; descartado para LLMs por alto costo computacional.
- Jang et al. (2022) — Knowledge Unlearning for Mitigating Privacy Risks: propone gradient ascent para unlearning en LMs; este paper lo extiende con random mislabeling para mayor estabilidad y tres escenarios de aplicación.
- Eldan & Russinovich (2023) — Who’s Harry Potter? Approximate Unlearning in LLMs: trabajo concurrente; aborda el mismo escenario de copyright con un enfoque basado en un modelo reforzado y diccionario de términos ancla en lugar de gradient ascent.
- Ouyang et al. (2022) — InstructGPT / Bai et al. (2022) — Constitutional AI: trabajos de referencia en RLHF para alineación; Yao et al. proponen el unlearning como alternativa más eficiente cuando solo se tienen muestras negativas.
- Carlini et al. (2021) — Extracting Training Data from LLMs: demuestra que los LLMs filtran datos de entrenamiento incluyendo contenido protegido y privado; motiva directamente los escenarios de copyright y privacidad de este paper.
- Pawelczyk et al. (2023) — In-Context Unlearning: propone unlearning mediante in-context learning sin modificar pesos; citado como alternativa con diferente trade-off (no modifica el modelo pero ocupa espacio de contexto).
Tags
machine-unlearning LLM contenido-tóxico copyright fine-tuning