Who's Harry Potter? Approximate Unlearning in LLMs
Qué hace
Propone una técnica para que Llama2-7b “olvide” los 7 libros de Harry Potter sin reentrenar el modelo desde cero. El problema central es copyright: los LLMs son entrenados sobre texto de internet que frecuentemente incluye obras protegidas, y reentrenar un modelo que costó más de 184.000 GPU-horas es completamente impráctico. La solución tarda ~1 hora de GPU en fine-tuning y borra efectivamente la capacidad del modelo de generar o recordar contenido específico de Harry Potter, manteniendo intacto su rendimiento en benchmarks estándar.
El método tiene tres componentes: (1) un modelo reforzado para amplificar y localizar el conocimiento HP-específico, (2) un diccionario de ~1.500 términos ancla con sus reemplazos genéricos, y (3) un fine-tuning del modelo base sobre etiquetas alternativas generadas combinando ambos.
Por qué fallan los enfoques ingenuos
Antes de describir el método, los autores argumentan en detalle por qué las dos ideas más obvias no funcionan. Esta discusión es uno de los aportes más valiosos del paper.
¿Por qué no funciona negar la función de loss?
La primera idea es simple: si el modelo predice bien el siguiente token del texto de HP, penalizarlo con una pérdida invertida. Pero esto falla por una razón fundamental: la mayoría de los tokens en cualquier texto son palabras comunes del lenguaje, no conocimiento específico del libro.
Ejemplo del paper: para la oración “Harry Potter went up to him and said, ‘Hello. My name is ____’“, si se aplica pérdida negativa cuando el modelo predice correctamente “Harry”, no se está desentrenando el libro de HP — se está desentrenando el significado de la frase “my name is”. El modelo aprende que después de “my name is” no viene un nombre, lo cual destruye conocimiento general de lenguaje.
¿Por qué no funciona el gradient ascent sobre tokens específicos?
Una variante más sofisticada sería solo aplicar el gradiente ascendente en los tokens claramente asociados a HP (nombres propios, lugares). Pero esto también falla:
Ejemplo del paper: para el prompt “Harry Potter’s two best friends are ____“, si se reduce la probabilidad de “Ron”, el modelo simplemente cambia a “Hermione”. Para suprimir ambas alternativas hay que hacer muchos pasos de gradiente, y como ambas tienen probabilidades muy altas desde el inicio, las señales de gradiente son pequeñas — la convergencia es muy lenta e inestable.
La pregunta correcta
Los autores reencuadran el problema: en lugar de preguntarse “¿cómo penalizo las predicciones HP-específicas?”, preguntan:
“¿Qué habría predicho un modelo que nunca fue entrenado con los libros de Harry Potter?”
Esta reformulación lleva a un enfoque constructivo: generar una distribución alternativa de predicciones y hacer fine-tuning hacia esa distribución, en lugar de alejarse de la distribución original.
Metodología
El método tiene tres componentes que se combinan para construir un dataset de fine-tuning con etiquetas alternativas.
Componente 1 — El modelo reforzado
Se toma Llama2-7b-chat-hf y se hace fine-tuning adicional sobre los propios libros de Harry Potter durante 3 épocas (context length 512, lr = 3·10⁻⁶, batch size 8, 16 gradient accumulation steps). Este modelo reforzado se vuelve extremadamente “obcecado” con HP: tiende a completar cualquier texto con referencias al universo del libro incluso cuando el prompt apenas lo sugiere.
¿Para qué sirve? El modelo reforzado actúa como un detector de conocimiento HP-específico. Si un token tiene probabilidad mucho más alta en el modelo reforzado que en el modelo base, ese token representa información que el modelo base aprendió del corpus HP. La diferencia entre ambas distribuciones localiza exactamente el conocimiento a borrar.
La fórmula para generar predicciones alternativas (“genéricas”) es:
\[v_{\text{generic}} := v_{\text{baseline}} - \alpha \cdot \text{ReLU}(v_{\text{reinforced}} - v_{\text{baseline}})\]con \(\alpha = 5\).
Intuición de la fórmula: Se toma la predicción del modelo base y se le resta, amplificada por \(\alpha\), la diferencia positiva entre el modelo reforzado y el base. El ReLU es clave: solo se substrae cuando el modelo reforzado asigna más probabilidad que el base — es decir, solo se penalizan los tokens que el reforzamiento específicamente amplificó. Los tokens que tienen alta probabilidad en ambos modelos (palabras comunes del lenguaje) no se ven afectados.
Limitación del modelo reforzado solo: En pasajes donde las completiones HP-específicas ya tienen probabilidad muy alta en el modelo base (por ejemplo, justo después de “Hermione y __”), el modelo reforzado apenas puede aumentarlas más, y la señal de la fórmula es débil. Para esos casos entra el segundo componente.
Componente 2 — Términos ancla y diccionario de reemplazos
Los términos ancla son expresiones idiosincrásicas del texto a olvidar: palabras o frases que son características y únicas del universo HP y que, si aparecen en un contexto, disparan el conocimiento asociado al libro.
¿Cómo se generan? Se le pasan fragmentos aleatorios del texto a GPT-4 con instrucción de extraer nombres, entidades y expresiones idiosincrásicas del texto, y para cada una generar un reemplazo alternativo que sea coherente en el texto pero no único del libro.
El diccionario resultante tiene aproximadamente 1.500 términos ancla. Ejemplos:
| Término ancla (HP) | Reemplazo genérico |
|---|---|
| Hogwarts | Mystic Academy |
| Ron | Tom |
| Harry | Jon |
| Hermione | (reemplazada) |
| Quidditch | Skyball |
| Apparition | Teleportation |
| Marauder’s Map | Explorer’s Chart |
| wands | gaze |
| Ravenclaw | the |
Nótese que los reemplazos no tienen por qué ser semánticamente equivalentes (ej. “wands” → “gaze”, “Ravenclaw” → “the”) — solo deben ser coherentes en el texto y no HP-específicos. La Figura 4 del paper muestra esto en acción: en el texto de fine-tuning, los tokens de las etiquetas objetivo que corresponden a términos ancla son sustituidos por sus equivalentes del diccionario.
¿Qué efecto tienen las anclas? Cubren el caso que el modelo reforzado no maneja bien: cuando el modelo base ya asigna probabilidad muy alta a términos HP-específicos, forzar directamente la predicción de un token genérico en su lugar es más efectivo que confiar en la señal de la diferencia de logits.
Algoritmo — Construcción del dataset de fine-tuning
El objetivo es construir un dataset de pares (texto HP original → distribución de predicciones genéricas) sobre el que luego se hace fine-tuning. Para cada bloque de 512 tokens del corpus HP se ejecutan los siguientes pasos:
Paso 1. Traducir el bloque con el diccionario de anclas
Se reemplaza cada término ancla por su equivalente genérico y se guarda el mapeo de posiciones (qué token en qué posición fue sustituido). El bloque resultante es el bloque traducido.
Ejemplo: el bloque original "Harry walked into Hogwarts and grabbed his wand" se convierte en "Jon walked into Mystic Academy and grabbed his gaze".
El bloque traducido se usará para obtener las predicciones del modelo base sobre texto sin referencias HP.
Paso 2. Obtener los logits del modelo base sobre el bloque traducido
\[\mathbf{v}_{\text{base}} = \text{logits}_{\theta_{\text{base}}}(\text{bloque\_traducido})\]Se pasa el bloque traducido por el modelo base y se extraen los logits — el vector de puntuaciones sin normalizar sobre todo el vocabulario, para cada posición del texto. Cualitativamente: estos logits representan “qué tokens predice el modelo base cuando el texto ya no contiene referencias HP”. Son la distribución de predicción de un modelo que nunca vio el universo HP en ese contexto.
Por qué el bloque traducido y no el original: si se usara el bloque original, el modelo base ya sería “experto” en HP y sus predicciones reflejarían ese conocimiento. Al traducir primero, se obtiene una distribución limpia de asociaciones HP.
Paso 3. Obtener los logits del modelo reforzado sobre el bloque original
\[\mathbf{v}_{\text{ref}} = \text{logits}_{\theta_{\text{reinforced}}}(\text{bloque\_original})\]Se pasa el bloque original (con los nombres HP reales) por el modelo reforzado y se extraen sus logits. Cualitativamente: el modelo reforzado, al haber sido entrenado intensivamente sobre los libros HP, amplifica exactamente los tokens asociados al universo HP. Sus logits más altos que los del modelo base señalan qué tokens son HP-específicos en ese contexto.
Ejemplo: para la posición donde el texto dice "Harry", el modelo reforzado asignará logit muy alto a tokens como "Potter", "Hermione", "Hogwarts" — mucho más alto que el modelo base sobre el bloque traducido.
Paso 4. Calcular el offset de reforzamiento
\[\mathbf{o} = \text{ReLU}(\mathbf{v}_{\text{ref}} - \mathbf{v}_{\text{base}})\]Se calcula la diferencia token a token entre los logits del modelo reforzado y los del modelo base, y se aplica ReLU (que pone a cero los valores negativos).
Qué mide esta diferencia: para cada token del vocabulario, ¿cuánto más probable lo hace el modelo reforzado respecto al modelo base? Un valor positivo grande en el token "Potter" significa que el modelo reforzado amplificó fuertemente ese token — es conocimiento HP-específico. Un valor cercano a cero o negativo significa que ese token es igual de probable en ambos modelos — es conocimiento general del lenguaje.
Por qué el ReLU: solo nos interesan los tokens que el modelo reforzado amplificó (diferencia positiva). Si el modelo reforzado asigna menos probabilidad a un token que el modelo base, ese token no es HP-específico y no queremos tocarlo. El ReLU descarta esas diferencias negativas, dejando solo la “huella HP” sobre los logits.
Ejemplo concreto: para la palabra “hermione” el offset sería muy alto; para “the” o “walked” el offset sería ~0.
Paso 5. Calcular las predicciones genéricas
\[\mathbf{v}_{\text{generic}} = \mathbf{v}_{\text{base}} - \alpha \cdot \mathbf{o}\]con \(\alpha = 5\).
Se toman los logits del modelo base (ya “limpios” porque vienen del bloque traducido) y se les resta el offset HP amplificado por \(\alpha\). Cualitativamente: se está sustrayendo activamente el conocimiento HP del modelo base. Los tokens que el modelo reforzado identificó como HP-específicos (offset alto) quedan fuertemente penalizados en los logits finales.
Interpretación: \(\mathbf{v}_{\text{generic}}\) aproxima la distribución de predicciones que tendría un modelo que nunca fue entrenado con los libros HP. No es perfecta (el modelo base ya tiene algo de conocimiento HP desde el preentrenamiento), pero es la mejor aproximación disponible sin reentrenar desde cero.
El rol de \(\alpha = 5\): amplifica el offset para garantizar que la señal HP quede efectivamente suprimida. Sin amplificación, la diferencia podría no ser suficiente para mover la distribución de predicciones de forma apreciable.
Paso 6. Construir el par de entrenamiento
Se agrega al dataset el par:
- Entrada (fuente): el bloque original con términos HP reales
- Etiqueta objetivo: los logits \(\mathbf{v}_{\text{generic}}\) calculados en el paso 5
El fine-tuning entrena al modelo para que, dado el texto HP original como contexto, sus predicciones se parezcan a \(\mathbf{v}_{\text{generic}}\) — es decir, para que reaccione al texto HP como si no lo conociera.
Importante: la etiqueta objetivo no es un token concreto sino una distribución sobre el vocabulario (un vector de logits). El fine-tuning minimiza la KL divergence entre la distribución del modelo en entrenamiento y esta distribución objetivo.
Manejo de inconsistencias de términos ancla
Un problema sutil: si el texto dice “Harry went up to him and said, ‘Hi, my name is Harry’“, siguiendo el algoritmo se fine-tunea el modelo sobre “Harry went up to him and said, ‘Hi, my name is Jon’” — lo cual crea una inconsistencia: “Harry” aparece antes en el mismo bloque pero no fue reemplazado. Los autores resuelven esto de dos formas:
- Cualquier aparición de un término ancla después de su primera ocurrencia en el bloque no se integra en la loss (se excluye de la función de pérdida).
- Se reducen las probabilidades de los logits correspondientes a las traducciones de términos ancla que ya aparecieron previamente en el mismo bloque.
Fine-tuning final
El modelo base se fine-tunea sobre el dataset generado durante 2 épocas, con lr = 10⁻⁶, batch size 8, 16 gradient accumulation steps. El paper reporta que ~150 pasos de gradiente son suficientes para lograr el unlearning efectivo.
Evaluación
Los autores diseñan métricas específicas para este problema porque los benchmarks estándar no capturan familiaridad con HP.
Familiarity score — basado en completions
Se generan 300 prompts sobre HP. Las completions del modelo se pasan a GPT-4, que las clasifica en cuatro categorías:
- Conocimiento explícito: la completion revela nombres o detalles únicos del libro (ej. menciona “Dumbledore”)
- Conocimiento temático: no es único de HP pero es típico de sus temas (magos, academia mágica) sin que el prompt lo sugiriera
- Familiaridad accidental: podría ser una coincidencia o adivinanza
- Sin familiaridad: no revela conocimiento del libro
El score cuenta solo categorías 1 y 2, con multiplicador 5 para la primera.
Familiarity score — basado en probabilidades
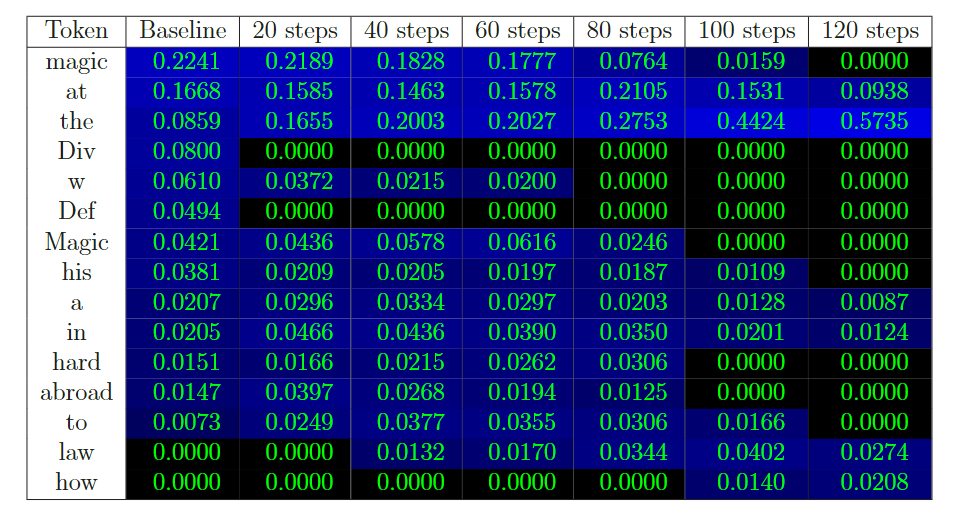
30 prompts específicos. Para cada uno, los posibles tokens siguientes se clasifican manualmente como “idiosincrásicos de HP” o “genéricos”. El score es la probabilidad total asignada a los tokens idiosincrásicos, promediada sobre los prompts.
Ejemplo concreto del paper: para el prompt “Harry Potter studies ____“, “magic” y “wizardry” son tokens idiosincrásicos; “the” es genérico. Después del unlearning, la probabilidad de “magic” cae de 0.2241 a 0.0000 y la de “the” sube de 0.0859 a 0.5735.
Resultados principales
Reducción de familiaridad
| Métrica | Modelo base | Tras ~120 pasos de fine-tuning |
|---|---|---|
| Familiarity (completions) | 0.290 | 0.007 |
| Familiarity (probabilidades) | 0.244 | 0.006 |
Reducción de más del 97% en ambas métricas, alcanzada en ~150 pasos de gradiente.
Preservación de capacidades generales
| Benchmark | Modelo base | Modelo fine-tuned |
|---|---|---|
| ARC-challenge | 0.440 | 0.414 |
| ARC-easy | 0.744 | 0.724 |
| BoolQ | 0.807 | 0.796 |
| HellaSwag | 0.577 | 0.557 |
| OpenBookQA | 0.338 | 0.328 |
| PIQA | 0.767 | 0.760 |
| WinoGrande | 0.663 | 0.657 |
Degradación mínima en todos los benchmarks (máximo ~2-3 puntos porcentuales).
Ejemplos de outputs antes y después
| Prompt | Antes del unlearning | Después del unlearning |
|---|---|---|
| “Who is Harry Potter?” | “Harry Potter is the main protagonist in J.K. Rowling’s series of fantasy novels…” | “Harry Potter is a British actor, writer, and director…” |
| “Harry Potter’s two best friends are” | “Ron Weasley and Hermione Granger” | “a talking cat and a dragon” |
| “Write a short story in the style of Harry Potter.” | “The Adventures of a Young Wizard…” | “It was a dark and stormy night, and I was all alone…” |
El modelo no dice “no sé” — genera texto fluido y coherente, pero desvinculado del universo HP.
Limitaciones
- Olvido de superconjunto: el método puede borrar inadvertidamente contenido relacionado pero no incluido en el corpus de unlearning (ej. contenido de Wikipedia sobre HP).
- Robustez adversarial: la evaluación basada en prompts puede ser “ciega” a métodos de extracción más adversariales. Trabajos posteriores (Shi et al. 2023) confirman que el conocimiento no se elimina completamente y puede recuperarse con técnicas de membership inference.
- Dependencia de idiosincrasia léxica: el método funciona especialmente bien con HP porque tiene ~1.500 términos únicos y nombres propios muy distintivos. Para contenido no-ficción (ideas, conceptos, perspectivas culturales), la densidad de términos ancla es mucho menor y el método presenta desafíos adicionales.
- GPT-4 para extracción de entidades: los autores usan GPT-4 para construir el diccionario, aunque mencionan que experimentos preliminares sugieren que la extracción de entidades puede ser efectiva incluso sin ese conocimiento previo.
Ventajas respecto a trabajos anteriores
- Primer método de unlearning efectivo para LLMs generativos: los trabajos anteriores se concentraban en clasificadores o proponían gradient ascent, que el paper demuestra empíricamente que falla.
- Reformulación constructiva: en lugar de alejarse de la distribución original (inestable), se construye una distribución objetivo alternativa y se fine-tunea hacia ella.
- Combinación de dos mecanismos complementarios: el modelo reforzado captura el conocimiento HP-específico en los logits; el diccionario de anclas cubre los casos donde la señal del logit es débil porque las predicciones HP ya tienen alta probabilidad desde el modelo base.
- Eficiencia extrema: 1 hora de GPU vs. 184.000 GPU-horas de preentrenamiento.
- Evaluación específica del dominio: diseñan familiarity scores con GPT-4 como juez, ya que los benchmarks estándar no capturan familiaridad con contenido específico.
Trabajos previos relacionados
El paper señala que la literatura de unlearning para modelos generativos era muy escasa al momento de su publicación; la mayoría de los trabajos existentes se concentraban en clasificadores. Identifica tres líneas previas: unlearning general en ML, trabajos sobre privacidad en LLMs, y un trabajo concurrente sobre desafíos de unlearning en LLMs.
- Cao & Yang (2015) — Towards Making Systems Forget with Machine Unlearning: trabajo fundacional del área; citado como referente de unlearning en ML general sobre clasificadores, cuyas técnicas no se trasladan directamente a LLMs generativos.
- Jang et al. (2022) — Knowledge Unlearning for Mitigating Privacy Risks: propone gradient ascent para unlearning de información privada en LMs; es el trabajo previo más cercano. Eldan & Russinovich lo evalúan críticamente: el gradient ascent (reversed loss) no funciona en su configuración porque desaprende lenguaje general en lugar de conocimiento específico.
- Yao et al. (2023) — Large Language Model Unlearning: trabajo concurrente que también aplica unlearning a LLMs para contenido tóxico y copyright; citado como trabajo simultáneo que discute desafíos y direcciones similares.
- Bourtoule et al. (2021) — Machine Unlearning via SISA: enfoque de reentrenamiento eficiente mediante shards; citado como el mejor baseline de reentrenamiento exacto que el paper busca superar en costo con su alternativa de fine-tuning localizado.
- Touvron et al. (2023) — Llama 2: el modelo base sobre el que se aplica el unlearning; su arquitectura transformer open-source lo hace el caso de uso central del experimento.
- Shi et al. (2023) — Detecting Pre-Training Data from the Likelihood Ratio: demuestra posteriormente que el método de Harry Potter no elimina completamente el conocimiento — puede recuperarse con técnicas de membership inference, subrayando la dificultad del unlearning verificable.
Tags
machine-unlearning copyright LLM fine-tuning conocimiento-específico