OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Qué hace
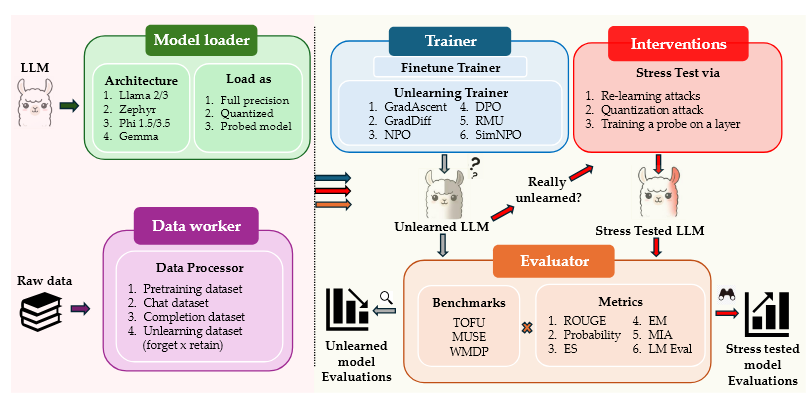
Presenta OpenUnlearning, un framework unificado de código abierto (MIT) para benchmarking de unlearning en LLMs. Integra 13 algoritmos, 16 métricas de evaluación y 3 benchmarks principales (TOFU, MUSE, WMDP) bajo una misma infraestructura. Hace dos contribuciones centrales: (1) una meta-evaluación de las métricas — mide qué tan fiables y robustas son las métricas de evaluación de unlearning en sí mismas — y (2) una comparación sistemática de 8 métodos usando esas métricas. Desde su apertura en marzo de 2025 acumula 250+ GitHub stars y 20.000+ descargas de modelos con 450+ checkpoints públicos.
Motivación: el problema de la fragmentación
Cada paper de unlearning propone un método nuevo y lo evalúa en un benchmark diferente con métricas diferentes, haciendo imposible comparar resultados entre trabajos. El paper A reporta “85% de forget quality” en TOFU, el paper B reporta “90%” en WMDP: no hay forma de saber cuál es mejor. Adicionalmente, varias métricas de evaluación han sido criticadas por ser poco confiables: algunos modelos “pasan” la evaluación estándar pero revelan el conocimiento ante parafraseos o cuantización.
OpenUnlearning resuelve ambos problemas: estandariza la comparación entre métodos y evalúa formalmente la calidad de las métricas.
Metodología
El framework
Usa Hydra para gestión de configuración — cada componente (dataset, método, métrica) es un YAML intercambiable, lo que permite lanzar un experimento nuevo con un solo comando. Agregar un método o métrica nueva requiere solo dos pasos: crear una clase handler y un YAML de configuración.
Componentes integrados:
| Componente | Variantes disponibles |
|---|---|
| Modelos | Llama-2, 3.1, 3.2; Zephyr-7B; Phi-1.5, 3.5; Qwen-2.5; Gemma |
| Algoritmos de unlearning | GradAscent, GradDiff, IdkDPO, IdkNLL, NPO, SimNPO, RMU, UNDIAL, AltPO, CE-U, PDU, WGA, SatImp |
| Datasets | TOFU (bios ficticias); WMDP (cyber, bio); MUSE (news, books) |
| Suites de evaluación | TOFU, MUSE, WMDP, LM Eval Harness |
| Métricas de memorización | Verbatim Prob./ROUGE; QA-ROUGE; Extraction Strength; Exact Memorization |
| Métricas de privacidad | Forget Quality; LOSS; ZLib; GradNorm; MinK; MinK++; Privacy Leakage |
| Métricas de utilidad | Truth Ratio; Model Utility; LM-Eval; Fluency |
| Stress tests | Relearning; Quantization; Probing |
Benchmarks cubiertos
El paper distingue dos tipos de unlearning:
Fine-grained (olvido de instancias específicas de entrenamiento):
- TOFU: 200 autores ficticios con 20 QA cada uno. Forget sets predefinidos (forget01/05/10 = 1%/5%/10% de datos). Modelo base: LLM de chat finetuneado.
- MUSE: unlearning de libros y artículos de noticias completos desde un LLM finetuneado. Mide memorización, conocimiento y privacidad.
- KnowUndo, LUME, PISTOL: benchmarks menores de copyright, datos sensibles, y relaciones estructurales respectivamente.
Open-ended (olvido de conceptos amplios sin corpus de olvido definido):
- WMDP: 3.668 preguntas de opción múltiple sobre conocimiento peligroso (bioseguridad, ciberseguridad, seguridad química). Ver Li et al. (2024).
- RWKU: entidades reales de Wikipedia.
- Who’s Harry Potter: olvido de entidad famosa.
Mejoras que OpenUnlearning agrega sobre los benchmarks originales:
- TOFU: preguntas parafraseadas, métricas de privacidad de MUSE (PrivLeak), nuevos ataques MIA con holdout datasets, reemplazo de Phi-1.5/Llama-2 por Llama-3 (1B/3B/8B), métricas Extraction Strength y Exact Memorization.
- MUSE: variantes adicionales de MIA, integración de métricas de otros benchmarks.
- Cross-benchmark: LM Eval Harness integrado para capacidades generales; métricas portables entre los tres benchmarks.
Meta-evaluación de métricas (Sección 4)
El paper propone el primer framework que evalúa las métricas de evaluación en sí mismas, según dos propiedades:
Faithfulness (fidelidad)
Una métrica es faithful si asigna consistentemente puntuaciones más altas a modelos que poseen el conocimiento objetivo que a los que no lo poseen.
Metodología: se construyen dos pools de 30 modelos cada uno:
- Pool positivo (P): modelos entrenados con el conocimiento objetivo en formatos diversos.
- Pool negativo (N): modelos entrenados sin el conocimiento objetivo usando perturbaciones y datos alternativos.
La faithfulness se mide como el AUC-ROC que separa las distribuciones de scores entre ambos pools:
\[\text{Faithfulness} = \text{AUC-ROC}(m(P),\ m(N))\]Testbed: TOFU forget10 (olvidar 10% de los datos = 400 ejemplos), Llama-3.2-1B.
Robustness (robustez)
Una métrica es robust si su veredicto no cambia ante intervenciones benignas (que no reintroducen conocimiento) y sí cambia ante intervenciones no benignas (que sí lo reintroducen).
Dos stress tests:
Robustez a cuantización (Q): mide si la métrica es estable antes/después de cuantizar el modelo a 4 bits (intervención benigna — no agrega conocimiento):
\[q = \frac{m_\text{unl}^\text{before}}{m_\text{unl}^\text{after}}, \qquad Q = \min(q,\ 1)\]Robustez a reaprendizaje (R): compara qué tan rápido recupera el score un modelo unlearned vs. un modelo retain al reentrenarlos sobre el forget set (intervención no benigna):
\[r = \frac{m_\text{ret}^\text{after} - m_\text{ret}^\text{before}}{m_\text{unl}^\text{after} - m_\text{unl}^\text{before}}, \qquad R = \min(r,\ 1)\]Un R bajo indica que el modelo unlearned reacquiere el conocimiento más rápido que el retain model — señal de que el olvido fue superficial.
Agregación mediante media harmónica (penaliza métricas fuertes en una dimensión pero débiles en otra):
\[\text{Robustness} = \text{HM}(R,\ Q), \qquad \text{Overall} = \text{HM}(\text{Faithfulness},\ \text{Robustness})\]Resultados de meta-evaluación
| Métrica | Overall ↑ | Faithfulness ↑ | Robustness ↑ | Q ↑ | R ↑ |
|---|---|---|---|---|---|
| Extraction Strength | 0.85 | 0.92 | 0.79 | 0.95 | 0.68 |
| Exact Memorization | 0.80 | 0.90 | 0.72 | 0.92 | 0.59 |
| Truth Ratio | 0.73 | 0.95 | 0.59 | 0.92 | 0.43 |
| Paraphrased Probability | 0.73 | 0.71 | 0.75 | 0.60 | 0.98 |
| Paraphrased ROUGE | 0.72 | 0.89 | 0.61 | 0.93 | 0.45 |
| Probability | 0.72 | 0.82 | 0.65 | 0.60 | 0.70 |
| ROUGE | 0.70 | 0.79 | 0.64 | 0.93 | 0.48 |
| Jailbreak ROUGE | 0.69 | 0.83 | 0.59 | 0.85 | 0.45 |
| MIA - ZLib | 0.71 | 0.92 | 0.57 | 0.56 | 0.59 |
| MIA - MinK | 0.67 | 0.93 | 0.52 | 0.48 | 0.57 |
| MIA - LOSS | 0.66 | 0.93 | 0.52 | 0.48 | 0.57 |
| MIA - MinK++ | 0.61 | 0.81 | 0.48 | 0.61 | 0.40 |
Hallazgos clave:
- Extraction Strength es la métrica más confiable globalmente (0.85): alta faithfulness (0.92) y muy buena robustez a cuantización (0.95); robustez a reaprendizaje moderada (0.68).
- Exact Memorization es segunda (0.80), con perfil similar.
- Truth Ratio tiene la faithfulness más alta de todas (0.95) pero baja robustez a reaprendizaje (0.43) — es fácil de “engañar” reentrenando.
- Paraphrased Probability es la más robusta a reaprendizaje (0.98) pero tiene baja faithfulness (0.71) — detecta recurrencia del conocimiento pero no lo identifica bien en primer lugar.
- Métricas MIA (ZLib, MinK, LOSS, MinK++): faithfulness alta (0.81–0.93) pero robustez sistemáticamente baja, especialmente a cuantización (0.48–0.61). La cuantización les hace “voltear” el veredicto — el hallazgo crítico de Zhang et al. que motivó este análisis.
- MIA - MinK++ es la peor métrica global (0.61).
Benchmarking de métodos de unlearning (Sección 5)
Se comparan 8 métodos sobre TOFU usando 10 métricas seleccionadas según los resultados de meta-evaluación: 4 de memorización (Extraction Strength, Exact Memorization, Truth Ratio, Paraphrased Probability), 4 de privacidad (MIA), 2 de utilidad (Model Utility, Fluency).
Setup: Llama-3.2-1B, BF16, A100, batch size 32, AdamW; 27 trials de tuning por método.
| Método | Aggregate ↑ | Memorización ↑ | Privacidad ↑ | Utilidad ↑ |
|---|---|---|---|---|
| Retain (gold standard) | 0.58 | 0.31 | 1.00 | 0.99 |
| SimNPO | 0.53 | 0.32 | 0.63 | 1.00 |
| RMU | 0.52 | 0.47 | 0.50 | 0.61 |
| UNDIAL | 0.42 | 0.27 | 0.48 | 0.78 |
| AltPO | 0.15 | 0.63 | 0.06 | 0.95 |
| IdkNLL | 0.15 | 0.08 | 0.17 | 0.93 |
| NPO | 0.15 | 0.52 | 0.06 | 0.99 |
| IdkDPO | 0.14 | 0.56 | 0.06 | 0.95 |
| GradDiff | 0.009 | 0.97 | 0.003 | 0.79 |
| Finetuned inicial (sin unlearning) | 0.00 | 0.00 | 0.10 | 1.00 |
Hallazgos clave:
- SimNPO es el mejor método (0.53): no sobre-olvida, preserva utilidad perfectamente (1.00) y alcanza la mejor privacidad (0.63). Su memorización (0.32) es baja pero comparable al retain model (0.31) — señal de que está bien calibrado.
- RMU es segundo (0.52): mayor reducción de memorización (0.47) pero utilidad notablemente dañada (0.61) — el costo de perturbar representaciones se nota.
- AltPO, NPO, IdkDPO (0.15/0.14): alta memorización (0.52–0.63) pero privacidad colapsada (0.06). El sobre-olvido los aleja tanto del modelo retain que las métricas de privacidad se hunden.
- GradDiff: memorización extrema (0.97 — el más agresivo de todos) pero aggregate de 0.009 y privacidad 0.003. Inutilizable en práctica.
- Brecha con el gold standard: el mejor método (SimNPO, 0.53) no alcanza al retain model (0.58). Ningún método resuelve unlearning completamente.
- Sensibilidad al ranking: cambiar el esquema de agregación o la estrategia de selección de hiperparámetros altera significativamente el orden de los métodos — el paper advierte que la metodología de ranking es tan importante como los métodos evaluados.
Datasets utilizados
- TOFU: benchmark principal de evaluación (forget10 para meta-evaluación, forget01/05/10 para comparación de métodos). Ver Maini et al. (2024).
- WMDP: conocimiento peligroso. Ver Li et al. (2024).
- MUSE: libros (Harry Potter) y artículos de noticias.
- MMLU, TruthfulQA: utilidad general vía LM Eval Harness.
- Modelo base en todos los experimentos: Llama-3.2-1B.
Resultados principales
- Extraction Strength y Exact Memorization son las métricas más confiables; las métricas MIA tienen alta faithfulness pero son frágiles ante cuantización.
- SimNPO y RMU son los mejores métodos en TOFU, con trade-offs distintos: SimNPO preserva utilidad, RMU olvida más agresivamente.
- Ningún método alcanza el gold standard (retain model). La brecha más estrecha es de 0.05 puntos aggregate.
- El orden de los métodos cambia según el esquema de ranking y la estrategia de tuning — la metodología de evaluación importa tanto como los métodos mismos.
- La fragmentación histórica del campo era real: métodos que reportaban resultados favorables habían elegido benchmarks donde tenían ventaja artificial.
Ventajas respecto a trabajos anteriores
- Primera meta-evaluación formal de métricas de unlearning con criterios cuantificables (faithfulness, robustez a cuantización, robustez a reaprendizaje).
- Infraestructura modular que reduce el tiempo de implementación de nuevos métodos de semanas a horas.
- 450+ checkpoints públicos con configuraciones diversas facilitan investigación posterior sin necesidad de reentrenar.
Trabajos previos relacionados
OpenUnlearning se sitúa en la intersección de tres líneas de trabajo previo: métodos de unlearning para LLMs, benchmarks de evaluación del olvido, y métricas de evaluación de memorización y privacidad.
- Maini et al. (2024) — TOFU: benchmark principal integrado; OpenUnlearning extiende TOFU con preguntas parafraseadas y nuevas métricas.
- Li et al. (2024) — WMDP: benchmark de seguridad integrado; RMU (método de WMDP) es uno de los dos mejores en la comparativa.
- Zhang et al. (2024) — NPO: uno de los métodos comparados; base de SimNPO.
- Fan et al. (2024) — SimNPO: el método más robusto en la comparativa de OpenUnlearning.
- Jang et al. (2022) — Knowledge Unlearning: trabajo pionero que establece métricas de memorización usadas en el framework.
- Eldan & Russinovich (2023) — Who’s Harry Potter: caso de uso en el benchmark MUSE integrado.
- Doshi et al. (2024) — Does Unlearning Truly Unlearn?: demuestra que métricas estándar son superficiales; motiva directamente la meta-evaluación de métricas de OpenUnlearning.
- Liu et al. (2024) — Rethinking Machine Unlearning: cuestiona criterios de evaluación actuales; sus propuestas informan el diseño del framework.
- Yao et al. (2023) — LLMU: gradient ascent y métodos base incluidos en OpenUnlearning.
- Jin et al. (2024) — RWKU: benchmark de conocimiento real integrado para evaluar generalización.
- Zhang et al. (2024) — Catastrophic Failure via Quantization: demuestra que PrivLeak “voltea” tras cuantización; motiva el stress test de robustez a cuantización de la meta-evaluación.
Tags
machine-unlearning benchmark framework comparación-métodos reproducibilidad