Feature-Selective Representation Misdirection for Machine Unlearning
Qué hace
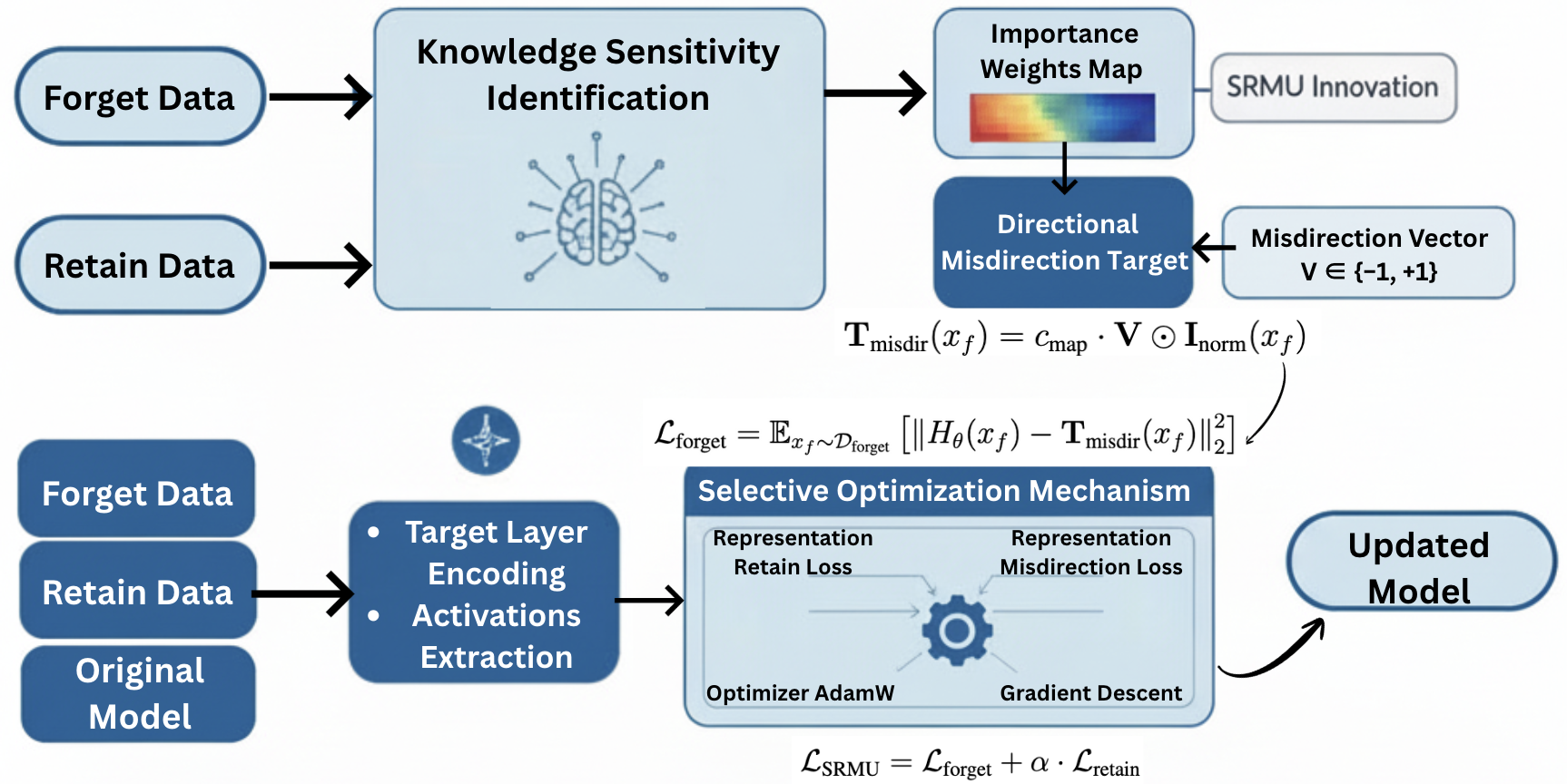
Propone SRMU (Selective Representation Misdirection for Unlearning), una extensión de RMU que resuelve el problema del alto entanglement: cuando el forget set y el retain set comparten vocabulario o conceptos relacionados (overlaps del 20–27%), los métodos de perturbación de representaciones existentes colapsan — o olvidan mal, o dañan el modelo. SRMU soluciona esto construyendo un mapa de importancia dinámico que identifica qué dimensiones del espacio de representación son específicas del forget set, y un vector de misdirección discreto que dirige la perturbación solo por esas dimensiones.
Metodología
Contexto: el problema del entanglement
RMU (base de este trabajo) empuja las representaciones internas del modelo en el forget set hacia un vector aleatorio fijo \(u\), usando una única capa \(l\). Esto funciona bien cuando el forget set y el retain set son semánticamente distintos. Cuando se solapan (ej. biología general vs. biología de patógenos peligrosos), la perturbación aleatoria también corrompe dimensiones que el modelo necesita para el retain set, degradando la utilidad general.
Elección de la capa \(l\): el paper sigue exactamente el mismo setup experimental que RMU para garantizar comparación justa — incluyendo la misma capa. En RMU, \(l\) se selecciona por grid search sobre las capas intermedias del modelo, evaluando el trade-off WMDP ↓ / MMLU ↑ para cada candidato. Para Zephyr-7B (32 capas en total), la capa elegida es \(l = 7\) — en el primer cuarto de la red, donde las representaciones ya codifican semántica pero aún no dominan el comportamiento de generación final. SRMU hereda esta elección directamente; la selectividad que aporta el mapa de importancia hace que la capa concreta sea menos crítica que en RMU, pero no se reporta un análisis de sensibilidad independiente sobre \(l\).
SRMU reemplaza el vector aleatorio \(u\) de RMU por un objetivo de perturbación adaptativo y selectivo construido en tres pasos.
Paso 1 — Construcción del mapa de importancia dinámico \(\mathbf{I}\)
Se extrae la activación promedio de la capa \(l\) sobre el forget set y el retain set:
\[\mathbf{v}_f = \mathbb{E}_{x_f \sim \mathcal{D}_\text{forget}}\left[ H^{(l)}(x_f) \right], \qquad \mathbf{v}_r = \mathbb{E}_{x_r \sim \mathcal{D}_\text{retain}}\left[ H^{(l)}(x_r) \right]\]Con estos vectores se computa la función de importancia \(\mathbf{I} = \phi(\mathbf{v}_f, \mathbf{v}_r)\). El paper propone y compara tres variantes:
SRMU-Ratio (la mejor en experimentos):
\[\mathbf{I}_\text{ratio} = \log\!\left(1 + \frac{\mathbf{v}_f}{\mathbf{v}_r + \varepsilon}\right)\]El argumento del logaritmo es \(1 + \mathbf{v}_f/\mathbf{v}_r\), es decir, cuántas veces más activa el forget set esa dimensión comparado con el retain set. Casos borde:
- Si \(\mathbf{v}_f \gg \mathbf{v}_r\): la ratio crece mucho, pero el \(\log\) la comprime — evita que dimensiones extremas monopolicen el mapa.
- Si \(\mathbf{v}_f \approx \mathbf{v}_r\) (dimensión entangled): ratio ≈ 1, \(\log(2) \approx 0.69\) — importancia moderada, no cero.
- Si \(\mathbf{v}_f \ll \mathbf{v}_r\): ratio ≈ 0, \(\log(1) = 0\) — la dimensión no se perturba.
El resultado es un mapa suave y continuo: todas las dimensiones donde el forget set tiene algo de activación reciben algo de perturbación, escalada logarítmicamente por cuánto dominan al retain set.
SRMU-Difference:
\[\mathbf{I}_\text{diff} = \text{ReLU}(\mathbf{v}_f - \lambda \cdot \mathbf{v}_r)\]Mide la diferencia absoluta entre ambas activaciones, con un factor \(\lambda\) que pondera cuánto “peso” tiene el retain set. Casos borde:
- Si \(\mathbf{v}_f > \lambda \cdot \mathbf{v}_r\): la dimensión es específica del forget set → importancia positiva proporcional a la diferencia.
- Si \(\mathbf{v}_f \leq \lambda \cdot \mathbf{v}_r\): ReLU devuelve 0 → la dimensión se ignora completamente.
Produce un mapa disperso y binario en espíritu: muchas dimensiones valen exactamente 0 (las compartidas con el retain set quedan completamente excluidas). Esto lo hace conservador pero puede perder dimensiones levemente entangled que igual contribuyen al conocimiento a olvidar.
SRMU-Product:
\[\mathbf{I}_\text{prod} = \frac{\mathbf{v}_f \odot \mathbf{v}_r}{\text{mean}(\mathbf{v}_f) \cdot \text{mean}(\mathbf{v}_r) + \varepsilon}\]El numerador \(\mathbf{v}_f \odot \mathbf{v}_r\) es alto cuando ambos sets activan la dimensión a la vez — es decir, detecta las dimensiones más entangled. El denominador normaliza por el producto de las medias globales, convirtiendo el valor en una especie de correlación relativa. Casos borde:
- Si \(\mathbf{v}_f^{(i)}\) y \(\mathbf{v}_r^{(i)}\) son ambos altos: numerador grande → alta importancia. Señala “esta dimensión es crucial para el forget set y el modelo la usa también para el retain set; hay que perturbarla con cuidado”.
- Si una de las dos es ≈ 0: producto ≈ 0 → importancia baja, independientemente de cuánto active la otra.
La lógica es opuesta a Difference: en lugar de excluir las dimensiones compartidas, las prioriza — parte de la hipótesis de que esas son las más difíciles de olvidar sin dañar el retain set, y por lo tanto las que más necesitan perturbación dirigida.
El mapa se normaliza a \([0, 1]\):
\[\mathbf{I}_\text{norm} = \frac{\mathbf{I}}{\max(\mathbf{I}) + \varepsilon_\text{norm}}, \qquad \varepsilon_\text{norm} = 10^{-8}\]Paso 2 — Vector de misdirección discreto \(\mathbf{V}\)
\(\mathbf{V}\) tiene la misma dimensión \(d\) que el hidden state de la capa \(l\) — típicamente \(d = 4096\) para un modelo de 7B parámetros. Es decir, hay un signo por cada coordenada del espacio de representación de esa capa.
En RMU, la dirección de perturbación es un vector unitario continuo aleatorio \(u \in \mathbb{R}^d\). SRMU lo reemplaza por un vector binario discreto:
\[\mathbf{V} \in \{-1, +1\}^d\]Cada componente se muestrea independientemente con probabilidad \(1/2\) para cada signo, y se fija antes del entrenamiento (igual que \(u\) en RMU). Al ser binario, cada dimensión tiene una polaridad fija: la dimensión \(i\) del hidden state va a ser empujada hacia arriba o hacia abajo en el espacio de activaciones, sin valores intermedios. Esto hace la dirección estable — siempre “apunta” al mismo lugar para todos los samples del forget set — e interpretable en el sentido de que se puede saber exactamente en qué dirección se perturbó cada coordenada.
La ablación demuestra que la aleatoriedad del signo por dimensión es clave: si se usa \(\mathbf{V} = +\mathbf{1}\) (todas las dimensiones hacia +1) o \(\mathbf{V} = -\mathbf{1}\) (todas hacia −1), el modelo colapsa (MMLU cae de 57% a 28%), porque esas direcciones uniformes coinciden con regiones del espacio de representación que el modelo usa para el retain set. La mezcla aleatoria de signos hace que el punto de destino sea efectivamente “ningún lugar semántico” — igual que el vector aleatorio de RMU, pero con polaridad discreta y consistente.
Paso 3 — Objetivo de perturbación y función de pérdida
El objetivo de misdirección para cada sample \(x_f\) combina el vector \(\mathbf{V}\) con el mapa de importancia:
\[T_\text{misdir}(x_f) = c_\text{map} \cdot \mathbf{V} \odot \mathbf{I}_\text{norm}(x_f)\]\(T_\text{misdir}(x_f)\) es un vector en \(\mathbb{R}^d\) — el mismo espacio que el hidden state \(H^{(l)}(x_f)\) — que actúa como destino artificial al que se quiere llevar la representación de \(x_f\). Dimensión a dimensión:
\[T_\text{misdir}^{(i)}(x_f) = c_\text{map} \cdot V^{(i)} \cdot I_\text{norm}^{(i)}\]- \(V^{(i)} \in \{-1, +1\}\): define hacia qué lado del eje \(i\) se empuja.
- \(I_\text{norm}^{(i)} \in [0, 1]\): regula cuánto se empuja en ese eje — si la dimensión \(i\) no es relevante para el forget set, \(I_\text{norm}^{(i)} \approx 0\) y el desplazamiento en esa coordenada es casi cero.
- \(c_\text{map}\): escala global que controla la magnitud total del desplazamiento.
Ejemplo concreto: suponer \(d = 4\) y que para el sample \(x_f\) = “cómo sintetizar un patógeno”, el mapa de importancia es \(\mathbf{I}_\text{norm} = [0.9,\ 0.1,\ 0.8,\ 0.05]\) (dimensiones 0 y 2 son muy relevantes para bioseguridad; 1 y 3 son genéricas). Si \(\mathbf{V} = [+1,\ -1,\ +1,\ -1]\) y \(c_\text{map} = 5\), entonces:
\[T_\text{misdir} = 5 \cdot [+1 \cdot 0.9,\ -1 \cdot 0.1,\ +1 \cdot 0.8,\ -1 \cdot 0.05] = [4.5,\ -0.5,\ 4.0,\ -0.25]\]La loss \(\mathcal{L}_\text{forget}\) entrenará al modelo para que \(H^{(l)}(x_f)\) se acerque a este vector. El resultado es que las dimensiones 0 y 2 (las que codifican el conocimiento peligroso) quedan desplazadas fuertemente hacia un punto arbitrario del espacio; las dimensiones 1 y 3 apenas se tocan.
donde \(c_\text{map} > 0\) es el escalar de magnitud (equivalente al \(c\) de RMU). A mayor \(c_\text{map}\), más lejos se empujan las representaciones; las dimensiones con mayor \(\mathbf{I}_\text{norm}\) reciben mayor desplazamiento.
La función de pérdida total es:
\[\mathcal{L}_\text{SRMU} = \underbrace{\mathbb{E}_{x_f \sim \mathcal{D}_\text{forget}} \left\| H_\theta^{(l)}(x_f) - T_\text{misdir}(x_f) \right\|_2^2}_{\mathcal{L}_\text{forget}} + \alpha \cdot \underbrace{\mathbb{E}_{x_r \sim \mathcal{D}_\text{retain}} \left\| H_\theta^{(l)}(x_r) - H_{\theta_0}^{(l)}(x_r) \right\|_2^2}_{\mathcal{L}_\text{retain}}\]- \(H_\theta^{(l)}\) es la activación de la capa \(l\) del modelo actualizado.
- \(H_{\theta_0}^{(l)}\) es la activación del modelo original congelado.
- Solo se actualizan los pesos de la capa \(l\); el resto del modelo permanece congelado.
- \(\alpha\) balancea olvido vs. preservación de utilidad (valor usado: \(\alpha = 1200\)).
Comparación con métodos anteriores (Tabla 1 del paper)
Feature Selectivo indica si el método distingue entre dimensiones del espacio de representación (o parámetros) según su relevancia para el forget set, en lugar de aplicar la misma perturbación a todo. ✗ significa que la intervención es uniforme o global: gradient ascent sube el gradiente en todos los parámetros por igual; RMU perturba todas las dimensiones de la representación con el mismo vector aleatorio \(u\). “Parcial” (DEPN) significa que identifica neuronas relevantes pero no hace una selección fina a nivel de dimensión dentro de cada neurona. ✓ (SRMU) significa que el mapa \(\mathbf{I}_\text{norm}\) pondera cada dimensión individualmente, concentrando la perturbación donde es necesaria y minimizándola donde no.
Robusto a alto entanglement indica qué tan bien funciona el método cuando el forget set y el retain set comparten vocabulario, conceptos o dominio — el escenario realista donde, por ejemplo, se quiere olvidar biología de patógenos pero conservar biología general. Los métodos logit-level como GA son los más frágiles (Bajo): al operar sobre probabilidades de salida sin distinguir qué representaciones internas se activan, cualquier overlap en el vocabulario hace que el olvido dañe también el retain set. RMU y Adaptive RMU logran un nivel Medio: perturbar representaciones es más quirúrgico que operar en logits, pero como la perturbación es aleatoria y uniforme sobre todas las dimensiones, con 20–27% de overlap las dimensiones compartidas se corrompen igual. SRMU alcanza Alto porque \(\mathbf{I}_\text{norm}\) detecta exactamente esas dimensiones compartidas y les asigna menor peso de perturbación (variante Difference) o perturbación más cuidadosa (variante Product), preservando el retain set incluso con overlap significativo.
| Método | Nivel de intervención | Mecanismo | Feature Selectivo | Robusto a alto entanglement |
|---|---|---|---|---|
| GA — Yao et al. (2023) | Logit | Gradient ascent | ✗ | Bajo |
| NPO — Zhang et al. (2024) | Logit | Optimización de preferencias | ✗ | Medio |
| UNDIAL (Dong et al., 2025) | Logit | Destilación logit a nivel token | ✗ | Bajo |
| RKLU (Wang et al., 2025) | Logit | Destilación selectiva a nivel token | ✗ | Medio |
| DEPN (Wu et al., 2023) | Neurona | Edición de neuronas | Parcial | Bajo |
| RMU — Li et al. (2024) | Representación | Perturbación aleatoria | ✗ | Medio |
| Adaptive RMU — Huu-Tien et al. (2025) | Representación | Perturbación aleatoria adaptativa | ✗ | Medio |
| SRMU (este paper) | Representación | Perturbación direccional selectiva | ✓ | Alto |
Datasets utilizados
- WMDP-Bio y WMDP-Cyber: evaluación principal en dos configuraciones:
- Bajo entanglement: retain set de Wikitext (sin overlap semántico).
- Alto entanglement: retain set del mismo dominio que el forget set (20.8% overlap unigramas en Bio, 27.5% en Cyber).
- Harry Potter corpus: benchmark literario mencionado como contexto de evaluación.
- TOFU: mencionado como benchmark de privacidad alternativo.
- Modelo base: Zephyr-7B en todos los experimentos.
Ejemplo ilustrativo
En el forget set de bioseguridad, las capas medias del modelo tienen ciertas dimensiones que se activan fuertemente cuando el texto trata síntesis de patógenos, pero también se activan (menos) al procesar biología general del retain set. RMU pertuba todas las dimensiones por igual con un vector aleatorio, dañando la biología general. SRMU computa que esas dimensiones tienen \(\mathbf{I}_\text{norm}\) alto (la ratio \(\mathbf{v}_f/\mathbf{v}_r\) es grande) y las pertuba proporcionalmente más; las dimensiones compartidas con el retain set tienen \(\mathbf{I}_\text{norm}\) bajo y reciben mínima perturbación.
Resultados principales
Configuración de bajo entanglement (retain set = Wikitext)
| Método | MMLU ↑ | WMDP-Bio ↓ | WMDP-Cyber ↓ | WMDP Avg ↓ |
|---|---|---|---|---|
| Base (Zephyr-7B) | 58.5 | 64.7 | 44.8 | 54.7 |
| LLMU | 44.7 | 59.5 | 39.5 | 49.5 |
| SCRUB | 51.2 | 43.8 | 39.3 | 41.6 |
| SSD | 40.7 | 50.2 | 35.0 | 42.6 |
| RMU | 56.9 | 28.8 | 28.0 | 28.4 |
| Adaptive RMU | 55.0 | 25.3 | 26.7 | 26.0 |
| SRMU | 57.1 | 28.5 | 25.8 | 27.2 |
En bajo entanglement SRMU iguala o supera a Adaptive RMU en olvido (27.2 vs 26.0 avg) con mayor preservación de utilidad (57.1 vs 55.0 MMLU). Define la frontera de Pareto en este régimen.
Configuración de alto entanglement (retain set del mismo dominio)
| Método | MMLU ↑ | WMDP-Bio ↓ | WMDP-Cyber ↓ | WMDP Avg ↓ |
|---|---|---|---|---|
| Base (Zephyr-7B) | 58.5 | 64.7 | 44.8 | 54.7 |
| RMU | 51.9 | 48.5 | 41.1 | 44.8 |
| Adaptive RMU | 51.2 | 49.3 | 37.7 | 43.5 |
| SRMU | 52.5 | 38.3 | 37.1 | 37.7 |
Este es el resultado clave del paper: con overlap del 20–27%, RMU y Adaptive RMU apenas logran olvido (WMDP avg baja de 54.7 a ~44). SRMU alcanza 37.7 — reducción real y significativa — siendo el único método efectivo en este régimen.
Ablación
| Variante | MMLU ↑ | WMDP Avg ↓ |
|---|---|---|
| Base | 58.5 | 54.7 |
| RMU baseline | 56.9 | 28.9 |
| SRMU completo | 57.1 | 27.2 |
| Sin \(\mathbf{V}\) ni \(\mathbf{I}_\text{norm}\) (sin actualizar) | 58.4 | 53.9 |
| Sin \(\mathbf{I}_\text{norm}\) (perturbación uniforme) | 51.7 | 25.0 |
| \(\mathbf{V}\) fijo en +1 | 28.8 | 24.3 |
| \(\mathbf{V}\) fijo en −1 | 24.8 | 25.6 |
| \(\mathbf{V}\) aleatorio en \([0, 1)\) | 56.7 | 27.6 |
La ablación confirma que ambos componentes son necesarios: sin \(\mathbf{I}_\text{norm}\) se puede olvidar más pero se destruye la utilidad; sin la dirección correcta de \(\mathbf{V}\) el modelo colapsa.
Ventajas respecto a trabajos anteriores
- Único método que logra olvido efectivo bajo alta superposición semántica entre forget y retain set.
- La selectividad por dimensión preserva capacidades del modelo no relacionadas con el conocimiento a olvidar.
- Mantiene la eficiencia de RMU: solo actualiza una capa, complejidad equivalente.
Trabajos previos relacionados
El paper organiza los antecedentes en tres categorías: técnicas de unlearning por nivel de intervención (logit, neurona, representación), métodos de unlearning en LLMs como field general, y benchmarks de evaluación.
- Cao & Yang (2015) — Towards Making Systems Forget with Machine Unlearning: Cao & Yang (2015) formaliza el problema de machine unlearning que SRMU extiende al dominio de LLMs con alta entanglement.
- Li et al. (2024) — The WMDP Benchmark (RMU): WMDP introduce RMU (Representation Misdirection for Unlearning), el método de referencia directa que SRMU extiende al agregar selectividad de features y vector de misdirección dirigida.
- Huu-Tien et al. (2025) — On Effects of Steering Latent Representation for LLM Unlearning (Adaptive RMU): Huu-Tien et al. propone Adaptive RMU que rescala el coeficiente de perturbación de RMU según normas de activación; es la línea base más directamente comparable con SRMU.
- Yao et al. (2024) — Machine Unlearning of Pre-trained LLMs (GA/LLMU): Yao et al. introduce gradient ascent y el método LLMU para LLMs, referenciados como baselines de nivel logit en las comparaciones experimentales.
- Zhang et al. (2024) — Negative Preference Optimization (NPO): NPO es un baseline de nivel logit que combina optimización de preferencias negativas para unlearning, incluido en la tabla comparativa.
- Maini et al. (2024) — TOFU: TOFU es un benchmark de unlearning para privacidad mencionado como alternativa al testbed principal WMDP.
- Eldan & Russinovich (2023) — Who’s Harry Potter: Who’s Harry Potter trata el borrado de contenido con derecho de autor en LLMs, benchmark alternativo citado en el contexto de evaluación.
- Jang et al. (2022) — Knowledge Unlearning for Mitigating Privacy Risks: Knowledge Unlearning propone gradient ascent a nivel de token para privacidad; representa la clase de métodos logit-level con los que se compara SRMU.
- Jin et al. (2024) — RWKU: RWKU benchmark de unlearning en contextos enciclopédicos del mundo real, mencionado en el contexto de evaluación general del campo.
Tags
machine-unlearning representaciones-internas residual-stream edición-liviana LLM