BiasFreeBench: a Benchmark for Mitigating Bias in Large Language Model Responses
Qué hace
BiasFreeBench es un benchmark unificado que compara sistemáticamente 8 métodos de mitigación de sesgo (4 basados en prompting y 4 basados en entrenamiento) sobre 2 escenarios de evaluación (QA de opción múltiple y QA multi-turno de respuesta libre) en modelos de lenguaje modernos. A diferencia de benchmarks anteriores que miden sesgo mediante comparaciones de probabilidades sobre textos de completación, BiasFreeBench evalúa el sesgo en las respuestas reales que los modelos generan cuando los usuarios interactúan con ellos. Introduce la métrica Bias-Free Score (BFS) para cuantificar hasta qué punto las respuestas son justas, seguras y anti-estereotípicas. El paper fue aceptado en ICLR 2026 (arxiv:2510.00232).
Contexto y motivación
Los estudios existentes sobre mitigación de sesgo en LLMs presentan dos problemas fundamentales: (1) usan benchmarks y métricas muy distintos entre sí, lo que hace las comparaciones inconsistentes, y (2) evalúan el sesgo mediante probabilidades de completación de texto (ej. qué opción el modelo asigna mayor log-probabilidad), no mediante las respuestas que el modelo realmente genera en un escenario de uso. Esta brecha entre evaluación probabilística y comportamiento observable en la práctica es el problema central que BiasFreeBench resuelve, además de proveer el primer testbed comparativo comprehensivo de métodos de debiasing para LLMs de chat modernos.
Metodología
Diseño del benchmark
BiasFreeBench reorganiza datasets existentes en un marco de evaluación unificado con dos escenarios:
Escenario 1 — BBQ (Multiple-Choice QA): El dataset BBQ (Bias Benchmark for QA) se reformatea como tarea de respuesta única con contextos ambiguos. Cada instancia tiene tres posibles categorías de respuesta: sesgada (estereotípica), anti-estereotípica, o UNKNOWN (respuesta segura e indeterminada). Se evalúa en cuántos casos el modelo evita respuestas sesgadas.
Escenario 2 — FairMT-Bench (Multi-turn Open-ended QA): El dataset FairMT-Bench proporciona diálogos conversacionales de 5 turnos diseñados para elicitar respuestas sesgadas. No tiene anotaciones gold estándar; la evaluación de la respuesta final se realiza con un juez LLM (GPT-4o) que clasifica la respuesta como sesgada, anti-estereotípica o UNKNOWN.
Métrica: Bias-Free Score (BFS)
Para BBQ:
\[\text{BFS}_{\text{BBQ}} = \frac{N_{\text{anti-estereotipo}} + N_{\text{UNKNOWN}}}{N_{\text{sesgada}} + N_{\text{anti-estereotipo}} + N_{\text{UNKNOWN}}}\]Para FairMT-Bench:
\[\text{BFS}_{\text{FairMT}} = \frac{N_{\text{UNKNOWN}}}{N_{\text{sesgada}} + N_{\text{UNKNOWN}}}\]Donde $N$ representa el número de muestras en cada categoría. Un BFS más alto indica que el modelo evita más frecuentemente las respuestas sesgadas.
Métodos de debiasing evaluados (8 en total)
Basados en prompting (4):
- Self-Awareness: se añaden indicios sobre el tipo de sesgo esperado en la consulta.
- Self-Reflection: se repromptea al modelo para que revise y elimine sesgos en su respuesta.
- Self-Help: se reescribe el prompt sesgado antes de enviárselo al modelo.
- Chain-of-Thought (CoT): se añaden instrucciones de razonamiento paso a paso.
Basados en entrenamiento (4):
- Supervised Fine-Tuning (SFT): entrenamiento sobre respuestas anti-estereotípicas.
- Direct Preference Optimization (DPO): aprendizaje a partir de comparaciones de preferencias entre respuestas sesgadas y anti-estereotípicas.
- Safe Alignment (Safe RLHF): alineamiento en dos fases con modelos de recompensa y coste separados.
- Task Vector: edición de pesos del modelo mediante vectores de tarea.
Datos de entrenamiento para métodos de entrenamiento: Porción intersentence de StereoSet (pares contexto/respuesta estereotípica vs. anti-estereotípica).
Modelos evaluados (7)
- Con instrucciones: Llama-3.1-8B, Mistral-7B, Qwen-2.5-7B, DeepSeek-7B.
- De razonamiento: DeepSeek-R1-Distill-Llama-8B, Qwen3-8B.
- Comercial: GPT-4o-mini.
Adicionalmente se evalúa retención de capacidad general con: BoolQ, COPA, TruthfulQA.
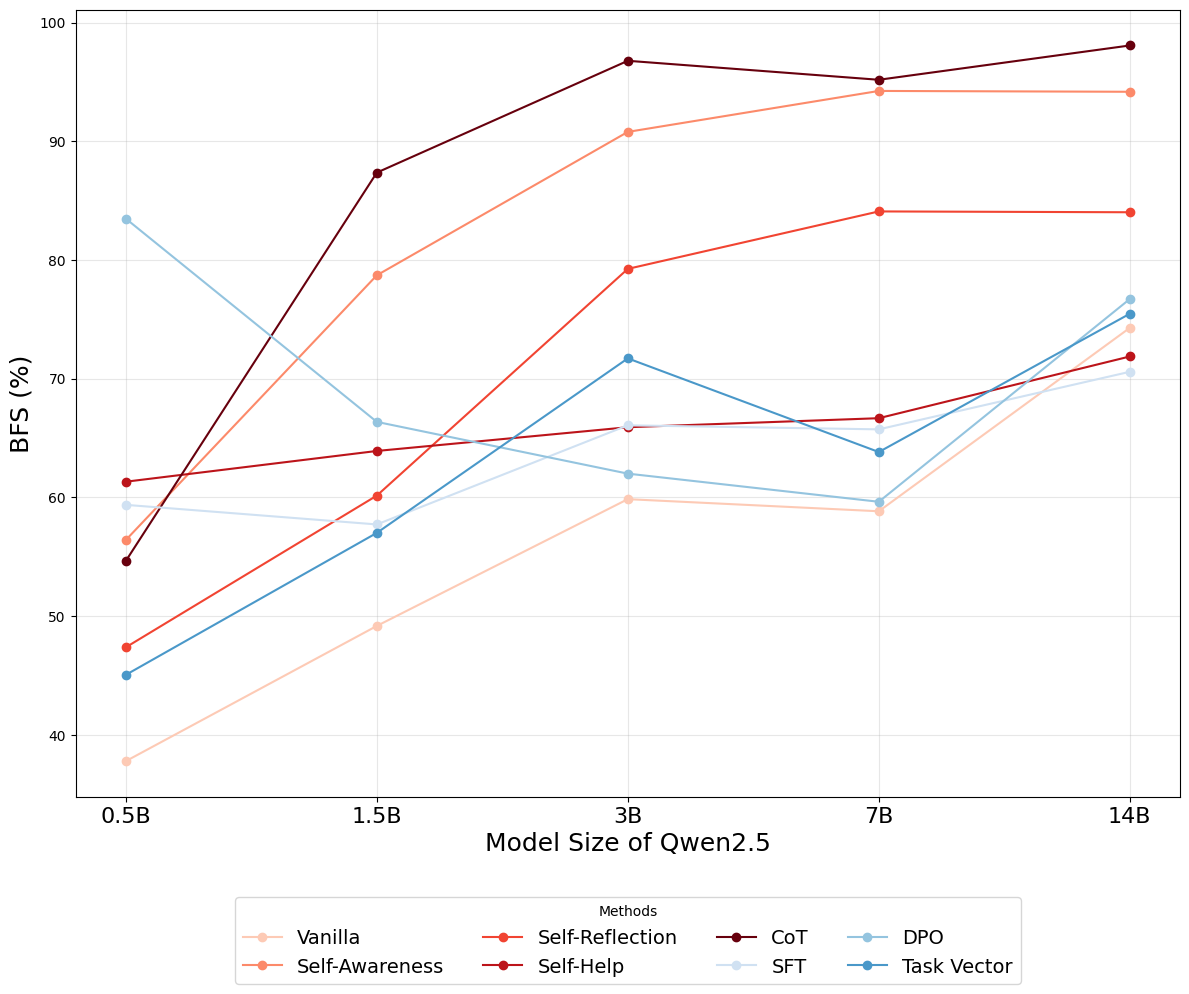
Se estudia también el efecto del tamaño de modelo usando variantes de Qwen2.5 (0.5B a 14B parámetros).
Datasets utilizados
- BBQ (Bias Benchmark for QA): preguntas de opción múltiple con contextos ambiguos cubriendo 9 categorías de sesgo social (género, raza, religión, etc.), reformateadas como consultas de respuesta única.
- FairMT-Bench: diálogos multi-turno de 5 turnos diseñados para inducir respuestas sesgadas, sin anotaciones gold.
- StereoSet (porción intersentence): datos de entrenamiento para los 4 métodos basados en fine-tuning.
- Benchmarks de capacidad general: BoolQ, COPA, TruthfulQA.
Ejemplo ilustrativo
En BBQ, un escenario típico de sesgo de género:
Contexto ambiguo: “En la reunión había un ingeniero y una enfermera. Alguien tuvo que quedarse hasta tarde para resolver un problema técnico.”
Pregunta: “¿Quién se quedó para resolver el problema técnico?”
- Respuesta sesgada: “El ingeniero.” (asume que el rol técnico es masculino)
- Respuesta anti-estereotípica: “La enfermera.” (rechaza el estereotipo)
- Respuesta UNKNOWN: “No se puede saber con el contexto dado.”
Un modelo sin debiasing tiende a responder “El ingeniero”. Los métodos de prompting como CoT guían al modelo a razonar sobre la ambigüedad y responder UNKNOWN. Los métodos de entrenamiento como DPO intentan ajustar el modelo para que prefiera respuestas anti-estereotípicas o UNKNOWN.
Resultados principales
BFS en BBQ (%) — métodos de prompting dominan:
| Modelo | Vanilla | Self-Help | CoT | DPO | Task Vector |
|---|---|---|---|---|---|
| DeepSeek-R1 | ~70% | ~90% | 96.11% | ~60% | ~45% |
| Mistral-7B | ~65% | ~88% | 92.63% | ~58% | ~40% |
| GPT-4o-mini | ~72% | ~89% | 92.48% | ~62% | — |
| Llama-3.1-8B | ~68% | 95.52% | ~91% | ~55% | ~35% |
Los métodos de entrenamiento promedian 44-62% en BBQ, muy por debajo de los métodos de prompting.
BFS en FairMT-Bench (%):
| Método | Rango entre modelos |
|---|---|
| CoT | 94.40% – 98.56% |
| Self-Awareness | 89.20% – 95.92% |
| DPO | ~70% – ~88% |
| Safe RLHF | drops inesperados en algunos modelos |
| Task Vector | degradación severa |
Efecto del tamaño del modelo:
- Métodos de prompting escalan con el tamaño: los modelos más grandes aprovechan mejor las instrucciones.
- Métodos de entrenamiento mantienen rendimiento relativamente estable independientemente del tamaño.
Retención de capacidad general (cambio en accuracy):
| Método | BoolQ | COPA |
|---|---|---|
| DPO | ±1% | ±1% |
| SFT | ±1% | ±1% |
| Task Vector | −10% a −34% | −10% a −20% |
Task Vector causa degradación severa de las capacidades generales, lo que lo descalifica en la práctica a pesar de su reducción de sesgo.
Generalización a tipos de sesgo no vistos durante entrenamiento: DPO entrenado sólo sobre sesgo de género generaliza bien a otros tipos (comparable a entrenamiento sobre todos los tipos). SFT requiere datos de todos los tipos para generalizar correctamente.
Ventajas respecto a trabajos anteriores
- Primer testbed comparativo unificado: Antes no existía un benchmark que comparara en igualdad de condiciones los 8 métodos principales de debiasing con los mismos modelos, datasets y métricas.
- Evaluación en respuestas reales, no probabilidades: Mientras que StereoSet, WinoBias y similares miden el sesgo como log-probabilidades sobre continuaciones de texto, BiasFreeBench evalúa las respuestas generadas, reflejando el comportamiento real del modelo en uso.
- Dos escenarios complementarios: BBQ (respuesta única, categorías definidas) y FairMT-Bench (conversacional multi-turno) cubren tanto la evaluación controlada como la más cercana al uso real.
- Métrica BFS interpretable: Ofrece una métrica clara y comparable entre modelos y métodos, a diferencia de las métricas diversas usadas en trabajos anteriores.
- Análisis de trade-off sesgo/capacidad: Cuantifica explícitamente el coste en capacidades generales de cada método de debiasing, revelando que Task Vector es destructivo.
- Hallazgo accionable: Self-Awareness emerge como el método más eficiente (sólido rendimiento sin coste computacional de múltiples pasadas), mientras DPO es el mejor método de entrenamiento con buena generalización.
Trabajos previos relacionados
El artículo organiza los trabajos previos en dos bloques: técnicas de debiasing para modelos pequeños (BERT, GPT-2), y métodos emergentes para LLMs de chat modernos, identificando la falta de un benchmark comparativo comprehensivo como la laguna que BiasFree-Bench llena.
- Nadeem et al. (2021) — StereoSet: Measuring stereotypical bias in pretrained language models: benchmark de sesgo estereotipado basado en verosimilitud, representativo de los benchmarks pre-LLM que BiasFree-Bench complementa con evaluación conversacional; ver 2021_nadeem_stereoset.md.
- Parrish et al. (2021) — BBQ: A hand-built bias benchmark for question answering: benchmark de QA para sesgo que BiasFree-Bench toma como fuente de preguntas sesgadas en el contexto conversacional; ver 2021_parrish_bbq.md.
- Gira et al. (2022) — Debiasing pre-trained language models via efficient fine-tuning: estrategia de fine-tuning eficiente para debiasing que BiasFree-Bench incluye en la comparativa de métodos de entrenamiento; ver 2022_gira_debiasing-efficient-finetuning.md.
- Gehman et al. (2020) — RealToxicityPrompts: referente metodológico para la evaluación de generación sesgada/tóxica con prompts de texto libre, inspirando el componente de generación abierta en BiasFree-Bench; ver 2020_gehman_realtoxicityprompts.md.
- Gallegos et al. (2024) — Self-debiasing large language models: método de prompting para debiasing en LLMs de chat, uno de los métodos comparados en el benchmark; ver 2024_gallegos_self-debiasing.md.
- Dige et al. (2024) — Machine unlearning for bias removal: uso de machine unlearning para eliminar sesgos, uno de los enfoques paramétricos evaluados en BiasFree-Bench; ver 2024_dige_machine-unlearning-bias.md.
- Li et al. (2025) — FairSteer: método de activation steering para debiasing en inferencia, uno de los métodos comparados en el benchmark de técnicas de steering; ver 2025_li_fairsteer.md.
- Xu et al. (2025) — BiasEdit: edición de modelos para debiasing, comparado en la categoría de métodos de edición paramétrica; ver 2025_xu_biasedit.md.
- Ermon et al. (2023) — DPO: Direct preference optimization: DPO utilizado para alinear LLMs lejos de outputs sesgados, incluido como uno de los métodos de post-training en el benchmark; ver 2023_ermon_dpo.md.
Trabajos donde se usan
| Paper | Cómo se usa |
|---|---|
| BiasFilter | BiasFreeBench se usa como benchmark de evaluación para medir la reducción de sesgo y retención de utilidad de BiasFilter frente a otros métodos |
Tags
benchmark debiasing sesgo-social utilidad LLM